The Mobility Service
The mobility service is portion of the Virginia Tech network experience where end devices connect wirelessly. Today, this is limited to Wi-Fi, but is not necessarily so in the future.
About this documentation
Target Audience
This documentation is primarily internal to the team managing/supporting the mobility service. It is also a convenient way to share ideas outside of the core team, and to encourage open development.
Contributing/feedback
All contributions and feedback, on the documentation and the service itself, are welcome.
Service Priorities
These are thoughts on what we prioritize or value for the Wi-Fi service specifically. This is not the core values set in the IT Strategic Plan, but is (in part) an extension of them, as it applies to specifically the Wi-Fi service. This is closely related to the AUAs, but is more general / broadly scoped in nature.
Key insights
- Our users set the expectations for the service.
- Our priorities are defined by the expectations.
- The priorities drive the features and properties of the system.
- All of this is constrained and guided by our core values.
What this looks like for Wi-Fi
Expectations
- Ubiquitous and seamless coverage
- Reliable access
- High bandwidth
- Reasonable latency
Priorities
- Robust
- Systems stay up
- Systems continue to provide service when they are up
- Systems are fault tolerant
- Debugable
- Flexible
- Well understood and solved problems should be solved out of the box
- The system should easily accommodate new ideas or deployments not considered by the vendor.
- Secure
- Coherent architecture
Properties
User end
- Frictionless access
- Latest standards
- Dual stacked now
- Single stack IPv6 limitations are external
Administrator end
- Fault tolerant
- Hardware should be able to fail without impacting users
- Replacing hardware should be low risk and (relatively) low effort
- API driven
- Complete
- Idempotent
- Single stacked IPv6
- IPv6 Addresses are not strings
- Fixing one part of the system should not depend another part of the system
- Centralized (or perhaps intent based) config (within what is allowed due to above)
- Integrated monitoring
- Observable
- Is the system itself healthy?
- What is the user facing status?
- Do I have the tools to see what is going on under the covers?
- Do I have tools to identify an unknown unknown problem?
- Configuration that is difficult (preferably impossible) to get out of sync.
- (Flexible)
- Sane defaults
- Extensive options
- Building-block config
- Clear and consistent mental model to the config
- Split control plane and data plane
- OOB access
- Key/cert based access
- Idempotent API/Config
- Auditable config
- Usable config system
- Easily spun up
- Lab purposes
- Ransomware recovery
- Life cycle
- Replacing hardware
- Hardware available
- Can the vendor do business?
- Is the vendor able to ship hardware?
- Can the vendor tell us how much we owe in support (in a reasonable time frame)?
- Can we predict how much we owe and what items we need?
Other notes / questions
- Ask for a packet walkthrough
See also
- IT Strategic Plan
- Strategic Recommendations for Cloud Computing
- Bryan Cantrill talks about priorities of Programming Languages (he calls them values, and what we call values he calls principles).
Services
This is a collection of the different ways a device can connect to the wireless network.
Full documentation is a work in progress, but for now, it includes high level information on the authentication used and mechanisms available to protect the network from a misbehaving device.
eduroam
eduroam is the primary wireless network at Virginia Tech.
Authentication
Virginia Tech users are authenticated with PEAP/MSCHAPv2. Because this is a thoroughly broken protocol, these credentials are used only for network authentication.
Network
All users, VT affiliates and roaming users on VT’s campus, land in
vlan-authenticated.
Remediation
We can remove a user or device from the network in two ways.
- Disable the credentials
- VT accounts can have the network entitlement removed, effectively revoking their authorization.
- By design, VT is unable to see the individual usernames for roaming users (e.g., a Radford user on VT’s campus). We can, however, see what institution their account is from. Therefore, to revoke access, we need to contact the user’s home institution. Since this is a process that can take some time and is not within our control, we can also block ALL authentication for that institution.
- Block the MAC address.
- This must be entered on each controller.
- The controller then denies all 802.11 authentication requests from that MAC, which prevents the device from even associating.
- This is becoming less effective as MAC randomization is increasing.
VT Open WiFi
The VT Open WiFi SSID is an open network with no captive portal.
This network should be used by devices that cannot or should not use eduroam. The main reasons for this are:
- The device cannot do 802.1X authentication (game consoles, Chromecasts, etc).
- The device belongs to a group (e.g., department) rather than an individual, and thus does not have eduroam credentials.
- The user is a guest (and has no eduroam IdP)
Authentication
Users can connect and use the network with or without authentication. Only MAC auth is used, so no matter what, the client sees the network as an open unauthenticated network. Auth is handled by FreeRADIUS, with OpenLDAP as a data store.
When any device connects to the open network:
- The wireless controller sends a RADIUS request with the connecting device’s
MAC address as the username and password.
- The format of the MAC address is configurable in the MAC auth profile on
the controller (
.mac_auth_profilein the API,aaa authentication mac <profile-name>in the CLI). We use lower-case and colon delimited.
- The format of the MAC address is configurable in the MAC auth profile on
the controller (
- If the device is not registered:
- The RADIUS server returns an Access-Reject
- If the device is registered as a personal device the RADIUS server returns
an Access-Accept with:
- VSA Aruba/Aruba-User-Role:
ur-registered-device - User-Name: <PID the device is registered to>
- VSA Aruba/Aruba-User-Role:
- If the device is registered as an organizational device, the RADIUS server
returns an Access-Accept with:
- VSA Aruba/Aruba-User-Role:
ur-registered-device - User-Name: <Org ID>
- VSA Aruba/Aruba-User-Role:
Any registered device is put in the Authenticated network; all other devices are in the unauthenticated network.
Registration
Devices can be registered in the NIS Portal. Devices can be registered as a personal device or an organizational device.
In either case, when a device is registered, the registration application uses
an API call (equivalent to the cli command aaa user delete mac <mac>) to
disconnect the device that was just registered.
This allows it to reconnect and reauthenticate, putting it in the correct
network.
Non-standard networks
These networks are not part of the “Virginia Tech network experience”. They are deployed as work-arounds on an as-needed basis. The hope is that as the wireless service grows/evolves, these on-offs will go away.
VT_TIX
This network exists to get the wireless ticket scanners online for athletics. Because we do not have the proper RF coverage in and around the stadium, these devices cannot use the standard networks, as thousands of other clients would also try to associate, choking out the scanners.
Network
Currently, this uses vlan-authenticated.
Ideally, this would use vlan-unauthenticated.
Athletics is going to verify if the scanners work on the unauthenticated network
by connecting them to VT Open WiFi.
An alternative would be to register the MAC addresses of the ticket scanners and have VT_TIX use the same aaa profile as VT Open WiFi.
Special considerations
- APs with the
VT_TIXnetwork on them have only theVT_TIXnetwork on them. This limits the use of the airspace. - The network is hidden to prevent devices from automatically associating.
Long term plan
We need a full deployment of APs in and around the stadium (and other athletic areas) that will support the 65,000+ people who are there for game day. Once we have this, the scanners can use the registered device service.
Authentication
None.
Remediation
- Block the client MAC on the controllers
- If the problematic device continues to reassociate with new randomized MAC addresses, shut down this network (disable the virtual-ap profile).
VTEvent
Important
The configuration for this was removed on 2026-01-29, as we are pretty sure this service has been superseded by VT Open WiFi. This documents what the service would look like, rough edges and subtleties included, if we need to spin it back up (which will probably happen with little notice).
One decision that would need to be made is what network devices land on:
- Unauthenticated: use
aaa-vtopenwifi; strong preference for this as the devices are actually unauthenticated (unless registered)- Authenticated: use
aaa-authenticated
Overview
VTEvent is for one-off events to get the support staff online when we are not
able to also provide connectivity to the large crowd.
It is a hidden open network.
For example, during Relay4Life, the support staff needs a network in the
Drillfield.
Adding the VT Open WiFi network may not be suitable, as a rapid deployment
unit would not be suitable for the density of clients.
Support
This is a very simple service.
There is no authentication.
The VLANs/subnets are the same as is used for VT Open WiFi
(vlan-unauthenticated and, if registered, vlan-authenticated).
As such, the most likely place for something to go wrong is communication.
Here are a few cases where something is most likely to go awry.
Hidden SSID
Because the SSID is hidden, the customer will need to type in the SSID exactly
correct, case sensitive.
There is no punctuation or any unexpected characters.
For reference, the SSID is VTEvent
Limited time
Is it before the event started? Is the event over? If so, the network may not be broadcasting. It goes up and down at the times agreed upon by the customer and NEO.
Down APs
Unlike the other two examples, this one is a technical issue, not a communications issue. Usually, the network will be on its own APs. As such, the problem may not be as obvious as normal.
Deployment and Cleanup
The nature of these events is that they are one offs, so it is easy to miscommunicate or leave cruft.
Communicate with the customer
Be sure to communicate with the customer what the name of the SSID is, and that the network is hidden. Because the network is hidden, the customer will need to type it in, so be verbose. Remember that SSIDs are case sensitive!
Create Jira tasks
When we deploy the network, or create a Jira task to deploy it, also create the task to shut it down, and put a fixed due date on it.
AOS config
aaa profile
aaa-vtopenwifi:
- Probably use this, see opening note
- See VT Open WiFi authentication for details.
aaa-authenticated:
- If we must
ssid-profile
ssid-vtevent:
- ESSID: VTEvent
- Hidden
- Normal data rates used elsewhere
virtual-ap profile
vap-vtevent:
- Just the aaa and ssid profiles from above
ap-group
apg-vtevent:
- For outdoor rapid deployment
- Virtual APs:
vap-vtevent
- dot11a:
rp5-outdoor - dot11g:
rp2-outdoor - Regulatory domain:
rdp-blacksburg
apg-<bldg>-vtevent:
- For indoor deployment
- Unlikely to be needed; strongly consider another solution
- Virtual APs:
vap-vtevent
- dot11a: match
apg-<bldg> - dot11g: match
apg-<bldg> - Regulatory domain:
rdp-blacksburg
Configuration
/md/vt
{
{
"a_basic_rates": {
"12": "12"
},
"a_beacon_rate": {
"a_phy_rate": "12"
},
"a_tx_rates": {
"12": "12",
"18": "18",
"24": "24",
"36": "36",
"48": "48",
"54": "54"
},
"advertise_ap_name": {},
"deny_bcast": {},
"essid": {
"essid": "VTEvent"
},
"g_basic_rates": {
"12": "12"
},
"g_beacon_rate": {
"g_phy_rate": "12"
},
"g_tx_rates": {
"12": "12",
"18": "18",
"24": "24",
"36": "36",
"48": "48",
"54": "54"
},
"hide_ssid": {},
"max_clients": {
"max-clients": 255
},
"mcast_rate_opt": {},
"profile-name": "ssid-vtevent"
}
],
"virtual_ap": [
{
"aaa_prof": {
"profile-name": "aaa-vtopenwifi"
},
"drop_mcast": {},
"profile-name": "vap-vtevent",
"ssid_prof": {
"profile-name": "ssid-vtevent"
}
}
]
}
/md/vt/swva
{
"ap_group": [
{
"dot11a_prof": {
"profile-name": "rp5-outdoor"
},
"dot11g_prof": {
"profile-name": "rp2-outdoor"
},
"profile-name": "apg-vtevent",
"reg_domain_prof": {
"profile-name": "rdp-blacksburg"
},
"virtual_ap": [
{
"profile-name": "vap-vtevent"
}
]
}
]
}
VTAthletics
Like VT_TIX, VTAthletics exists to connect support staff in a
crowded space.
However, it is more general purpose, allowing connectivity even for non VT
personnel.
Network
All clients connect to vlan-authenticated.
Although a PSK perhaps better thought of as an authorization mechanism,
necessity demands on campus access (see below).
Special considerations
- The network is not hidden, to allow for ease of use.
- Users need to be able to print, and thus need to “on campus” access.
- APs with the
VTAthleticsnetwork on them must not have general access networks on them (e.g.,eduroam,VT Open WiFi, etc). This helps to protect the airspace. - Ugh, PSK:
- As of 2026-01-30, this is our only PSK network.
- The key needs rotated on a regular basis.
- PSK isn’t really authentication, but we pretend like it is.
- All the concerns of a shared credential.
Long term plan
Like VT_TIX, the first hurdle is RF.
To solve this, we need a full deployment for the stands and other crowded areas.
The second hurdle is network access.
The most likely solution here is for guest accounts on eduroam.
Authentication
A regularly rotated PSK.
Remediation
- Block the client MAC on the controllers
- If the problematic device continues to reassociate with new randomized MAC addresses, change the PSK or shutdown the network (disable the virtual-ap profile).
HokiesTicketsFree
This network exists so patrons can access their digital tickets for sporting
events.
It is effectively a rebrand of VT Open WiFi.
Network
Authentication and connectivity is the same as VT Open WiFi.
We anticipate most users will be guests and end up on vlan-unauthenticated.
Special considerations
- Generally on outdoor APs covering large groups of people
- Needed in the same places at
VT_TIX, but must not be on the same APs asVT_TIX. If a guest (or even several guests) cannot connect to access their ticket, they are the only ones affected. If the scanners cannot connect, no one can enter. - Athletics likes the tickets branding. We’ve just about convinced them otherwise. Neither NEO nor athletics is terribly worried about it, though.
Long term plan
Replace HokiesTicketsFree with VT Open WiFi.
Carilion Networks
Virginia Tech Carilion school of Medicine has a colocation at Carilion Roanoke Memorial Hospital. As we are running the wireless network in some of these spaces, we need to also make the Carilion networks available.
Carilion specifies the ESSIDs, authentication servers, and all layer 3 aspects of the network.
SSIDs
Carilion-Wireless-WPA_Carilion-Wireless-WPACarilion-AppNet_Carilion-AppNet
Networks
vlan-carilion-wireless-wpa:- Used by all clients on
Carilion-Wireless-WPAand_Carilion-Wireless-WPA - VLAN ID 305
- Used by all clients on
vlan-carilion-appnet:- Used by all clients on
Carilion-AppNetand_Carilion-AppNet - VLAN ID 327
- Used by all clients on
In both cases, the VLAN is trunked to Carilion, where all layer 3 is managed by them. This includes the gateway, DHCP, DNS, etc.
Authentication
All four networks are 802.1X networks that authenticate against the same servers, all of which are run by Carilion:
caril-prd-nps01(172.16.254.28)caril-prd-nps02(172.16.254.26)caril-prd-nps03(172.16.254.30)
Locally bridged networks
Some locations where we have deployed remote access points (RAPs), we want the
traffic to stay local to where the AP is instead of coming back to campus.
These virtual AP profiles use the -bridged suffix.
Currently, this is only the case at GCAPS, where the local network is managed by VTTI, not central IT..
Deployment Info
Domain
VT’s deployment of the Aruba Mobility system uses the domain
mobility.nis.vt.edu.
All hostnames are relative to this domain.
For example, the hostname foo has the FQDN foo.mobility.nis.vt.edu and the
hostname foo.dev has the FQDN foo.dev.mobility.nis.vt.edu.
Configuration Hierarchy
Design
/
├── mm
│ └── mynode
└── md
└── [org]
└── [region]
└── [cluster]
└── [device]
/,/mm,/md, and/mm/mynodeare created by the system and cannot be removed/and/mdshould never be modified
Implementation
/
├── mm
│ ├── isb-mm-1
│ └── isb-mm-2
└── md
└── vt
├── swva
│ ├── bur
│ │ ├── bur-md-1
│ │ ├── bur-md-2
│ │ ├── bur-md-3
│ │ └── bur-md-4
│ ├── col
│ │ ├── col-md-1
│ │ ├── col-md-2
│ │ ├── col-md-3
│ │ └── col-md-4
│ ├── res
│ │ ├── res-md-1
│ │ ├── res-md-2
│ │ ├── res-md-3
│ │ └── res-md-4
│ └── vtc
│ ├── vtc-md-1
│ └── vtc-md-2
└── nova
└── equinix
├── equinix-md-1
└── equinix-md-2
Configuration prefixes
| Configuration Item | Prefix | Configuration tier |
|---|---|---|
aaa authentication captive-portal | cp- | org |
aaa authentication dot1x | dot1x- | org |
aaa authentication mac | mac- | org |
aaa authentication-server radius | asr-<server>-<service> | mm/org |
aaa profile | aaa- | org |
aaa server-group | sg- | mm/org |
ap regulatory-domain-profile | rdp- | region |
ap-group | apg- | region |
ip access-list session (allows) | acl-allow- | org |
ip access-list session (denies) | acl-deny- | org |
ip access-list session (mixed/captive) | acl-control- | org |
lcc-cluster group-profile | lcc- | cluster |
mgmt-server profile | ms- | cluster |
netdestination6 | nd6- | org |
netdestination | nd- | org |
rf arm-profile | arm- | region |
rf dot11-6GHz-radio-profile | rp6- | region |
rf dot11a-radio-profile | rpa-, rp5- | region |
rf dot11g-radio-profile | rpg-, rp2- | region |
user-role | ur- | org |
vlan-name | vlan- | org |
wlan he-ssid-profile | hessid- | org |
wlan ht-ssid-profile | htssid- | org |
wlan ssid-profile | ssid- | org |
wlan virtual-ap | vap- | org |
VLAN / subnet architecture
VLAN / subnet classifications
The Zero Trust principle says that it doesn’t matter what network a client is coming from. The application should implement it’s own authentication and security controls. Taking this to heart, we do not attempt to implement application security at the network layer.
However, it is , practical to make some broad classifications.
Authenticated
- IPv4: RFC 1918 (
172.16.0.0/12) - IPv6: Globally routed
- Considered “on campus” All authenticated devices land in the same network and have no restrictions.
Our assertion to application administrators is that we know (or can find) the owner of a device on this network.
Notably, by this criteria, a PSK network counts as unauthenticated (though PSK networks are only one-offs, which tend to bend the rules anyway).
Unauthenticated
- IPv4: CG-NAT (
100.64.0.0/10) - IPv6: Globally routed
- Considered “off campus”, that is, the same as traffic from the Internet
- Traffic from this network to campus is hair-pinned at the border
There are no network ACLs artificially limiting access. However, there are services that require being connected to an “on campus” network to use them, which the unauthenticated network is not. Some services that do not work from the unauthenticated network include:
- Zoom rooms
- Digital key access for physical doors
Connected… somewhere
Unfortunately, the real world is messy and things sometimes need their own networks. Notable examples of this include:
- Co-location networks where we pass the clients off to a different entity’s layer 2 connection (e.g., VTC).
- Remote locations where we want to bridge the traffic to the local (to the AP) network (e.g., gcaps).
- Special L2 or multicast connections (e.g., precor stuff)
In this case we use the nomenclature “connected” to indicate that we are not specifying the network where we normally would (see below).
VLAN assignment
The standard networks (eduroam and VT Open WiFi) use user roles to assign the VLAN.
One-off networks are by nature unauthenticated and often need a special VLAN. When using the standard unauthenticated network, they use the corresponding user role. Otherwise, they use a role that does not have the VLAN set (see below) and the VLAN is set on the Virtual AP profile.
VLAN Names
vlan-authenticated and vlan-unauthenticated
As one might expect, these map the authenticated and unauthenticated VLANs. Which exact VLAN ID this maps do depends on which cluster the user is connected to.
vlan-*
Everything else is used to label one-off networks. These are still mapped at the controller, though typically it is a one-to-one mapping.
User Roles
All roles apply basic ACLs to protect the network (prevent clients from acting as a DHCP server or sending RAs, etc).
ur-authenticated
- One of the “standard” roles
- Assigns the authenticated vlan
- All eduroam devices get this role
- Registered devices on VT Open WiFi get this role
- Not to be confused with the preconfigured
authenticatedrole
ur-unauthenticated
- One of the “standard” roles
- Assigns the unauthenticated vlan
- Devices that fail MAC auth on VT Open WiFi get this role
- Used by one-off networks that do not need a special VLAN
ur-connected
- Used only by (some) one-off networks
- Does not assign a VLAN; this must be done by the Virtual AP profile (or be bridged locally)
- These networks are treated as unauthenticated
AAA Profiles
aaa-eduroam and `aaa-vtopenwifi
The AAA profile for the eduroam and VT Open WiFi networks, including RF variants such as for large classrooms. See their respective pages for details.
aaa-eduroam-bridged
The same as aaa-eduroam, except it assigns the ur-connected role so the
traffic can be bridged locally instead of being tunneled back to the wireless
gateway.
aaa-authenticated, aaa-unauthenticated, and aaa-connected
These are (or may be) used by one-off networks to always put clients in the respective user role.
Production
Mobility Conductors
The devices formerly known as “Mobility Masters” (MMs).
Physical
- model: hw-mm-10k
- vlan: 100
- VRRP ID 1
| Hostname | Serial | MAC | IPv4 | IPv6 |
|---|---|---|---|---|
isb-mm | 128.173.32.36 | 2607:b400:2:2000:0:173:32:36 | ||
isb-mm-1 | TWK7K3503H | 20:4c:03:8f:53:1a | 128.173.32.34/27 | 2607:b400:2:2000:0:173:32:34/64 |
isb-mm-2 | TWF5K350V3 | 20:4c:03:0e:e0:44 | 128.173.32.35/27 | 2607:b400:2:2000:0:173:32:35/64 |
Mobility Devices (MDs)
Burruss
Management
| Hostname | Serial | MAC | IPv4 | IPv6 |
|---|---|---|---|---|
bur-md-1 | DL0001328 | 00:1a:1e:03:01:98 | 172.16.1.141/25 | 2607:b400:66:6000:0:16:1:141/64 |
bur-md-2 | DL0001122 | 00:1a:1e:02:d8:b0 | 172.16.1.142/25 | 2607:b400:66:6000:0:16:1:142/64 |
bur-md-3 | DL0001099 | 00:1a:1e:02:d9:70 | 172.16.1.143/25 | 2607:b400:66:6000:0:16:1:143/64 |
bur-md-4 | DL0001321 | 00:1a:1e:03:00:a8 | 172.16.1.144/25 | 2607:b400:66:6000:0:16:1:144/64 |
- Model: A7240XM
- VLAN: 399
- AP Discovery VRRP:
172.16.1.150 - AP Discovery VRRPv6:
2607:b400:66:6000:0:16:1:150 - Out of Band:
bur-oob-01.oob.cns.vt.edu
Cluster
| Hostname | VRRP ID | IPv4 VIP | IPv6 VIP |
|---|---|---|---|
bur-md-1 | 220 | 172.16.1.151 | 2607:b400:66:6000:0:16:1:151/64 |
bur-md-2 | 220 | 172.16.1.152 | 2607:b400:66:6000:0:16:1:152/64 |
bur-md-3 | 220 | 172.16.1.153 | 2607:b400:66:6000:0:16:1:153/64 |
bur-md-4 | 220 | 172.16.1.154 | 2607:b400:66:6000:0:16:1:154/64 |
vlan-unauthenticated
- VLAN: 804
- IPv4:
100.64.0.0/16 - IPv6:
2607:b400:a00:2::/64
vlan-authenticated
| Hostname | VLAN ID | IPv4 | IPv6 |
|---|---|---|---|
bur-md-1 | 1350 | 172.29.0.11/16 | 2607:b400:26:0:29:0:11/64 |
bur-md-2 | 1350 | 172.29.0.12/16 | 2607:b400:26:0:29:0:12/64 |
bur-md-3 | 1350 | 172.29.0.13/16 | 2607:b400:26:0:29:0:13/64 |
bur-md-4 | 1350 | 172.29.0.14/16 | 2607:b400:26:0:29:0:14/64 |
Coliseum
Management
| Hostname | Serial | MAC | IPv4 | IPv6 |
|---|---|---|---|---|
col-md-1 | DL0001121 | 00:1a:1e:02:d8:90 | 172.16.1.11/25 | 2607:b400:64:4000:0:16:1:11/64 |
col-md-2 | DL0001357 | 00:1a:1e:03:03:08 | 172.16.1.12/25 | 2607:b400:64:4000:0:16:1:12/64 |
col-md-3 | DL0001106 | 00:1a:1e:02:d8:f0 | 172.16.1.13/25 | 2607:b400:64:4000:0:16:1:13/64 |
col-md-4 | DL0001362 | 00:1a:1e:03:02:78 | 172.16.1.14/25 | 2607:b400:64:4000:0:16:1:14/64 |
- Model: A7240XM
- VLAN: 299
- AP Discovery VRRP:
172.16.1.20 - AP Discovery VRRPv6:
2607:b400:64:4000:0:16:1:20 - Out of Band:
col-oob-05.oob.cns.vt.edu
Cluster
| Hostname | VRRP ID | IPv4 VIP | IPv6 VIP |
|---|---|---|---|
col-md-1 | 220 | 172.16.1.21 | 2607:b400:64:4000:0:16:1:21/64 |
col-md-2 | 220 | 172.16.1.22 | 2607:b400:64:4000:0:16:1:22/64 |
col-md-3 | 220 | 172.16.1.23 | 2607:b400:64:4000:0:16:1:23/64 |
col-md-4 | 220 | 172.16.1.24 | 2607:b400:64:4000:0:16:1:24/64 |
vlan-unauthenticated
- VLAN: 805
- IPv4:
100.65.0.0/16 - IPv6:
2607:b400:a00:3::/64
vlan-authenticated
| Hostname | VLAN ID | IPv4 | IPv6 |
|---|---|---|---|
col-md-1 | 1250 | 172.30.0.11/17 | 2607:b400:24:0:0:30:0:11/64 |
col-md-2 | 1250 | 172.30.0.12/17 | 2607:b400:24:0:0:30:0:12/64 |
col-md-3 | 1250 | 172.30.0.13/17 | 2607:b400:24:0:0:30:0:13/64 |
col-md-4 | 1250 | 172.30.0.14/17 | 2607:b400:24:0:0:30:0:14/64 |
precor
- precor-cc vlan: 3553
- precor-guest vlan: 3554
Residential
Management
| Hostname | Serial | MAC | IPv4 | IPv6 |
|---|---|---|---|---|
res-md-1 | DL0001365 | 00:1a:1e:03:00:d8 | 172.17.1.11/24 | 2607:b400:64:ba00:0:17:1:11/64 |
res-md-2 | DL0001319 | 00:1a:1e:03:01:90 | 172.17.1.12/24 | 2607:b400:64:ba00:0:17:1:12/64 |
res-md-3 | DL0001387 | 00:1a:1e:03:11:10 | 172.17.1.13/24 | 2607:b400:64:ba00:0:17:1:13/64 |
res-md-4 | DL0001417 | 00:1a:1e:03:0f:f8 | 172.17.1.14/24 | 2607:b400:64:ba00:0:17:1:14/64 |
- Model: A7240XM
- VLAN: 3199
- AP Discovery VRRP:
172.17.1.20 - AP Discovery VRRPv6:
2607:b400:64:ba00:0:17:1:20 - Out of Band:
col-oob-05.oob.cns.vt.edu
Cluster
| Hostname | VRRP ID | IPv4 VIP | IPv6 VIP |
|---|---|---|---|
res-md-1 | 220 | 172.17.1.21 | 2607:b400:64:ba00:0:17:1:21/64 |
res-md-2 | 220 | 172.17.1.22 | 2607:b400:64:ba00:0:17:1:22/64 |
res-md-3 | 220 | 172.17.1.23 | 2607:b400:64:ba00:0:17:1:23/64 |
res-md-4 | 220 | 172.17.1.24 | 2607:b400:64:ba00:0:17:1:24/64 |
vlan-unauthenticated
- VLAN: 806
- IPv4:
100.66.0.0/64 - IPv6:
2607:b400:a00:12::/64
vlan-authenticated
| Hostname | VLAN ID | IPv4 | IPv6 |
|---|---|---|---|
res-md-1 | 3200 | 172.31.0.11/17 | 2607:b400:b4:1800:0:31:0:11/64 |
res-md-2 | 3200 | 172.31.0.12/17 | 2607:b400:b4:1800:0:31:0:12/64 |
res-md-3 | 3200 | 172.31.0.13/17 | 2607:b400:b4:1800:0:31:0:13/64 |
res-md-4 | 3200 | 172.31.0.14/17 | 2607:b400:b4:1800:0:31:0:14/64 |
Equinix
Management
| Hostname | Serial | MAC | IPv4 | IPv6 |
|---|---|---|---|---|
equinix-md-1 | BB0001058 | 00:1a:1e:00:14:30 | 45.3.106.2/24 | 2607:b400:803:0:0:3:106:2/64 |
equinix-md-2 | BB0001964 | 00:1a:1e:00:99:70 | 45.3.106.3/24 | 2607:b400:803:0:0:3:106:3/64 |
- Model: A7220
- VLAN: 2701
- AP Discovery VRRP: N/A
- AP Discovery VRRPv6: N/A
- Out of Band:
nvc-pbx-zpe.oob.vtnis.net
Cluster
| Hostname | VRRP ID | IPv6 VIP |
|---|---|---|
equinix-md-1 | 220 | 2607:b400:803:0:0:3:106:4 |
equinix-md-2 | 220 | 2607:b400:803:0:0:3:106:5 |
- Authenticated vlan: 2700
- Unauthenticated vlan: 808
vlan-unauthenticated
- VLAN: 808
- IPv4:
100.96.0.0/15 - IPv6:
2607:b400:a04:1::/64
vlan-authenticated
- VLAN: 2700
- IPv4:
172.25.192.0/19 - IPv6:
2607:b400:810::/64
VTC
Management
| Hostname | Serial | MAC | IPv4 | IPv6 |
|---|---|---|---|---|
vtc-md-1 | DL0003369 | 00:1a:1e:04:b1:10 | 172.16.247.11/23 | 2607:b400:62:1400:0:16:247:11/64 |
vtc-md-2 | DL0003377 | 00:1a:1e:04:b1:18 | 172.16.247.12/23 | 2607:b400:62:1400:0:16:247:12/64 |
- Model: A7240XM
- VLAN: 100
- AP Discovery VRRP:
172.16.247.20 - AP Discovery VRRPv6:
2607:b400:0062:1400:0:16:247:20/64 - Out of Band:
vtc-oob-01.oob.cns.vt.edu
Cluster
| Hostname | VRRP ID | IPv4 VIP | IPv6 VIP |
|---|---|---|---|
vtc-md-1 | 220 | 172.16.247.21 | 2607:b400:62:1400:0:16:247:11/64 |
vtc-md-2 | 220 | 172.16.247.22 | 2607:b400:62:1400:0:16:247:12/64 |
vlan-unauthenticated
- VLAN: 809
- IPv4:
100.70.0.0/16 - IPv6:
2607:b400:a02:1::/64
vlan-authenticated
| Hostname | VLAN ID | IPv4 | IPv6 |
|---|---|---|---|
vtc-md-1 | 1750 | 172.20.24.2/22 | 2607:b400:2e:0:0:30:128:11/64 |
vtc-md-2 | 1750 | 172.20.24.3/22 | 2607:b400:2e:0:0:30:128:12/64 |
Carilion networks
| Hostname | Carilion-AppNet | Carilion-Wireless-WPA |
|---|---|---|
| VLAN ID | 327 | 305 |
vtc-md-1 | 172.16.185.3/24 | 172.16.226.3/23 |
vtc-md-2 | 172.16.185.4/24 | 172.16.226.4/23 |
Dev
Mobility Conductors
| NOTE | The IPv4 address listed here are reserved, but not used |
- Model: MM-VA-500
- VLAN 115
- VRRP ID 239
| Hostname | Product key# | IPv4 | IPv6 |
|---|---|---|---|
mm.dev | 198.82.169.232 | 2001:468:c80:210f:0:133:6fe8:c4ef | |
mm-1.dev | MM603F362 | 198.82.169.233/24 | 2001:468:c80:210f:0:15c:3ecf:1a84/64 |
mm-2.dev | MM2D6D975 | 198.82.169.234/24 | 2001:468:c80:210f:0:1d2:4cad:7ff7/64 |
Mobility Devices
Coliseum
In band Management
| Hostname | Serial | MAC | Model | IPv6 |
|---|---|---|---|---|
col-md-5.dev | BB0002131 | 00:1a:1e:00:ab:38 | A7220 | 2607:b400:64:4000:0:16:1:15/64 |
col-md-6.dev | BB0002505 | 00:1a:1e:00:be:00 | A7220 | 2607:b400:64:4000:0:16:1:16/64 |
- VLAN: 299
- AP Discovery VRRP:
172.16.1.19 - AP Discovery VRRPv6:
2607:b400:64:4000:0:16:1:19
OOB Management
| Hostname | IPv6 |
|---|---|
col-md-5.dev | 2607:b400:e1:4000:0:0:0:15/64 |
col-md-6.dev | 2607:b400:e1:4000:0:0:0:16/64 |
col-md-7.dev | 2607:b400:e1:4000:0:0:0:17/64 |
Cluster
| Hostname | VRRP ID | IPv4 VIP | IPv6 VIP |
|---|---|---|---|
col-md-5.dev | 219 | 172.16.1.25 | 2607:b400:64:4000:0:16:1:25 |
col-md-6.dev | 219 | 172.16.1.26 | 2607:b400:64:4000:0:16:1:26 |
col-md-7.dev | 219 | 172.16.1.27 | 2607:b400:64:4000:0:16:1:27 |
vlan-guest
| Hostname | VLAN ID | IPv4 | IPv6 |
|---|---|---|---|
col-md-5.dev | 801 | 172.25.16.15/22 | 2607:b400:a00:1:0:25:16:15/64 |
col-md-6.dev | 801 | 172.25.16.16/22 | 2607:b400:a00:1:0:25:16:16/64 |
col-md-7.dev | 801 | 172.25.16.17/22 | 2607:b400:a00:1:0:25:16:17/64 |
vlan-user
| Hostname | VLAN ID | IPv4 | IPv6 |
|---|---|---|---|
col-md-5.dev | 1250 | 172.30.0.15/17 | 2607:b400:24:0:0:30:0:15/64 |
col-md-6.dev | 1250 | 172.30.0.16/17 | 2607:b400:24:0:0:30:0:16/64 |
col-md-7.dev | 1250 | 172.30.0.17/17 | 2607:b400:24:0:0:30:0:17/64 |
Lab
These are placeholder addresses, as these devices do not currently exist.
Management
| Hostname | lab host | MAC | IPv4 | IPv6 |
|---|---|---|---|---|
lab-md-1.dev | adder | 172.16.19.131/28 | 2607:b400:62:6d40:0:16:19:131/64 | |
lab-md-2.dev | cottonmouth | 172.16.19.132/28 | 2607:b400:62:6d40:0:16:19:132/64 |
- Model: N/A
- VLAN: 1499
- AP Discovery VRRP:
172.16.19.135 - AP Discovery VRRPv6:
2607:b400:62:6d40:0:16:19:135 - Out of band: N/A
APs
- IPv4 subnet:
172.16.19.144/28 - IPv6 subnet:
2607:b400:62:6d80::/64
Central on Prem
As with other things, the domain is mobility.nis.vt.edu.
For example, the hostname central has the FQDN central.mobility.nis.vt.edu.
| Hostname | Interface | IPv4 |
|---|---|---|
central | ens1f0 | 198.82.169.222/24 |
central-node-1 | ens1f0 | 198.82.169.223/24 |
central-node-2 | ens1f0 | 198.82.169.224/24 |
central-node-3 | ens1f0 | 198.82.169.225/24 |
central-node-4 | ens1f0 | 198.82.169.226/24 |
central-node-5 | ens1f0 | 198.82.169.227/24 |
Additional VIP hostnames:
central-centralapigw-centralccs-user-api-centralsso-central
POD IP Range: 10.0.0.0/16
Service IP Range: 10.1.0.0/16
iLO Configuration
Access credentials
- Local credentials only
- See password repository for details
Network
iLO Dedicated Network Port > IPv4:
- Not posting IPs because iLO is hella insecure. They are documented in the NEO password repo.
- DNS:
172.19.128.3 - IPv6 is currently not configured.
iLO Dedicated Network Port > SNTP:
- Disable DHCPv4/6 Supplied Time Settings
- Disable Propagate NTP Time to Host
- Primary Time Server: 172.19.131.253
- Secondary Time Server: conehead or grub
- Time Zone: Bogota, Lima, Quito, Easter Time(US & Canada) (GMT-05:00:00) NOTE: changing SNTP values will likely require an iLO reset.
Monitoring
SNMP
Management > SNMP Settings:
- System location: ISB 118
- System contact: nis-wifi-g@vt.edu
- System role: Central on Prem
- System Role Detail: Node 1, Node 2, …
- Disable SNMPv1
- SNMPv3 Users:
- Security Name: nisnmp
- See password repo for credentials
- User Engine ID: blank
- SNMP Alert Destinations:
- akips.nis.ipv4.vt.edu
- Trap Community: blank
- SNMP Protocol: SNMPv3 Inform
- SNMPv3 User: nisnmp
Syslog
Management > Remote SNMP:
- Enable iLO Remote Syslog
- Remote Syslog Port: 514
- Remote Syslog Server: akips.nis.ipv4.vt.edu
Disable iLO Federation
iLO Federation > Setup:
- Delete the default group
- Disable multicast options:
- iLO Federation Management
- Multicast Discovery
IPv6
IPv6 is not supported at all. There is no way to configure an IPv6 address. Not only that, but when configuring the networks settings, we see:
Created symlink /etc/systemd/system/basic.target.wants/disable-ipv6.service → /etc/systemd/system/disable-ipv6.service.
smtp
Allowlist for mailrelay.smtp.vt.edu:
198.82.169.222,central.mobility.nis.vt.edu,"Central on Prem neo-central@vt.edu","NIS"
198.82.169.223,central-node-1.mobility.nis.vt.edu,"Central on Prem neo-central@vt.edu","NIS"
198.82.169.224,central-node-2.mobility.nis.vt.edu,"Central on Prem neo-central@vt.edu","NIS"
198.82.169.225,central-node-3.mobility.nis.vt.edu,"Central on Prem neo-central@vt.edu","NIS"
198.82.169.226,central-node-4.mobility.nis.vt.edu,"Central on Prem neo-central@vt.edu","NIS"
198.82.169.227,central-node-5.mobility.nis.vt.edu,"Central on Prem neo-central@vt.edu","NIS"
Parts for redundancy
iLO Administrator and firmware password
The iLO “Administrator” account uses a password derived from the baseband serial number. This is done by the COP installation media. The same password is used for access to the firmware interface.
NOTE: This means that the serial numbers of the nodes are sensitive information! They are stored in the NEO password vault.
The script itself derives the password with the following commands (and some unnecessary file and variable creation…):
dmidecode -t baseboard \
| grep Serial \
| grep -o '[^ ]\+$' \
| md5sum \
| grep -Eo '^[^ ]+' \
| cut -c1-8
We can simplify this to:
dmidecode -s baseboard-serial-number | md5sum | head -c 8
Managing the RAID from a live environment
HPE has a variation of secure boot enabled, so we cannot just boot to whatever we want. However, secure boot is just looking for something signed by Canonical… so just grab Ubuntu and be off. Other distros signed with common keys may or may not work, but COP is built on Ubuntu 20.04.6, so that is the least likely to cause issues.
Unlike the COP ISO, the Ubuntu image can be dd’d to a USB drive to create a
bootable media.
iLO can also be used to mount virtual media to boot from.
Add HPE repositories
The ssacli utility allows us to reconfigure the RAID setup.
The best way to get this is by adding the HPE software delivery repository
Management Component Pack.
/etc/apt/sources.list.d/mcp.list:
# HPE Management Component Pack
deb https://downloads.linux.hpe.com/SDR/repo/mcp focal/current non-free
Now, install the keys:
curl https://downloads.linux.hpe.com/SDR/hpPublicKey2048.pub | sudo apt-key add -
curl https://downloads.linux.hpe.com/SDR/hpPublicKey2048_key1.pub | sudo apt-key add -
curl https://downloads.linux.hpe.com/SDR/hpePublicKey2048_key1.pub | sudo apt-key add -
Then update the repositories:
sudo apt update
Convert array to RAID 10
This will take a long time. If building a new system, create a new array instead of migrating an existing one.
# ssacli
=> ctrl slot=0 ld 1 add drives=allunassigned
=> ctrl slot=0 ld 1 show status
logicaldrive 1 (3.49 TB, RAID 0): Transforming, 0.83%
=> ctrl slot=0 ld 1 show status
logicaldrive 1 (3.49 TB, RAID 0): Transforming, 0.83%
=> ctrl slot=0 ld 1 modify raid=1+0
=> ctrl slot=0 ld 1 show status
logicaldrive 1 (3.49 TB, RAID 1+0): Transforming, 0.07%
=> ctrl slot=0 ld 1 show status
logicaldrive 1 (3.49 TB, RAID 1+0): OK
=>
Build a new RAID 10 array
This is a destructive process, but much faster than migrating an array. It is necessary to install COP from an ISO afterwards.
# ssacli
=> ctrl slot=0 ld 1 delete
[confirm]
=> ctrl slot=0 create type=ld drives=allunassigned raid=1+0
=>
Drive replacement (RAID 0)
A failed drive in a RAID 0 array is catastrophic, thus re-installing COP from the ISO afterwards is required.
- Physically replace the bad drive with a good one
- Reboot the system
- Press
F9during the boot to enter System Utilities, a BIOS like environment. You may need to pressF1to continue past the warning message (telling you a drive has failed and been replaced). - Select “System Configuration”
- Select “Embedded RAID 1: HPE Smart Array P408i-a SR Gen 10”
- Select “Array Configuration”
- Select “Manage Arrays”
- Select “Array A”
- Select “List Logical Drives”
- Select “Logical Drive 1 (…)”
- Select “Re-Enable Logical Drive”
- Confirm that you want to Re-Enable the Logical Drive. We are not expecting the data to be recoverable.
- Exit the menus until you can exit the system utilities. Re-enabling the array does not count as a change, so there is no need to save.
SSO / SAML
Configuration
The IdP can be setup with the metadata URL:
- prod: https://middleware.vt.edu/metadata/idp-prod.xml
- dev: https://middleware.vt.edu/metadata/idp-dev.xml
Attribute Release: See Middleware’s documentation.
- Email Address:
eduPersonPrincipalName - First Name:
givenName - Last Name:
sn - Idle Session Timeout (Minutes): 60
- HPE GreenLake Attribute:
hpe_ccs_attribute(see below and grouper for details)
Attributes
The HPE GreenLake platform Customer ID can be found on the GreenLake side, when managing the account, as the “Account ID”. The Central Application ID is not the customer ID that is found on the central side when clicking on the user icon in the top right. The only way we have found to see this ID is to setup SAML auth, then for a domain, click “View SAML Attribute”.
Entity ID
https://sso-central.mobility.nis.vt.edu
Sign-On URL
https://sso-central.mobility.nis.vt.edu/sp/ACS.saml2
HPE GreenLake platform Customer ID
c21f1ba2aa9311eeb8641623aaf5e6a6
HPE GreenLake platform ID
00000000-0000-0000-0000-000000000000
Applications
| Name | ID |
|---|---|
| Aruba Central (On-Premises) | 7c8fe57a-d6b7-481c-aafa-cf0c2e1e686e |
Grouper
Management
This is the stuff that helps us manage the wireless network. Various tools, automation, etc.
Down APs
Tools like AirWave or AKiPS will discover what APs are on the network and let us know when something goes down. This is good, but it doesn’t tell us if the AP is expected to be down, replaced, or if a new AP has never come up. That is, it doesn’t capture intent.
ATLAS is the authoritative source for intent and what is expected. The controllers are the authoritative source for what is reality.
Possible discrepancies
A non-exhaustive list of things that could be wrong:
- An AP is down
- Listed in Atlas
- Not listed or down on the controller
- Different AP is present
- MAC does not match
- AP was not removed
- Not listed in Atlas (at least, not in the list of what is expected)
- Is listed on the controller
Script
Here is a start to a script that does this comparison. Notably, it does not yet talk to ATLAS. Without real data, it is of limited use, even as a PoC.
AP Provisioning
AP Provisioning is automated with some code written by the NIS dev team. It is triggered two different ways: on demand and scheduled.
Core
Information gathering
The code ingests the MAC address of an AP. It queries the MM to determine the AP’s:
- name
- group
- AAC
It then queries the AAC to get the AP’s LLDP neighbor information, where it finds:
- The name of the switch
- The interface description
NOTE: For the AAC, the MM returns the IP address as used by the AP. This IP address is how the code connects to the AAC.
Generating the name and group
It uses the LLDP information to determine the building abbreviation and the HLINK, if it exists. This is used to determine the expected group and name.
The AP name takes the form BLDG-HLINK, where:
BLDGis the uppercase building abbreviationHLINKis the HLINK (or link identifier for older installations)
The AP group takes the form apg-bldg where:
apgis a fixed prefixbldgis the lowercase building abbreviation
Edge cases
- The HLINK may not exist yet (this is particularly common in new installations). In this case, the AP’s MAC address is used in place of an HLINK.
- The AP may already be provisioned in a custom group.
If the AP’s current group is of the form
apg-bldg-foo, where-foois some suffix beginning with a-, then this is considered a match, and the program will not move the AP to a different group.
Creating a group
When a program provisions an AP, it checks to make sure that the AP group exists. If it does not, it creates a group at the region level (see Configuration Hierarchy) which looks like:
{
"dot11a_prof": {
"profile-name": "rpa-default"
},
"profile-name": "apg-bldg",
"reg_domain_prof": {
"profile-name": "rdp-blacksburg"
},
"virtual_ap": [
{
"profile-name": "vap-eduroam"
},
{
"profile-name": "vap-vtopenwifi"
}
]
}
Regulatory domain
The regulatory domain is chosen based on the AAC prefix.
- If the AAC starts with,
col,bur, orresthen the RDP is set tordp-blacksburg - If the AAC starts with
vtc, then the RDP is set tordp-roanoke. - If the AAC starts with
nvc, then the RDP is not set. - If the AAC starts with anything else, the group is not created.
On Demand
- AP boots
- MD sends an SNMP trap to AKiPS
- Provisioning app periodically (every 2s) pull trap events from AKiPS
(specifically, the host
akips.nis.vt.edu) - waits 5 minutes
- App looks up the AAC for that MD from the MM
- probably with the
show ap detail wired-mac xx:xx:xx:xx:xx:xxcommand (via api)
- probably with the
This is how APs are provisioned when they are deployed. This also fixes APs that are moved to a new location.
- tool checks akips every 2s
- events are added with a 5 min delay
- 4 attempts with at a 5 minute interval before giving up
Scheduled
The reconciler runs at 06:00 ET daily. It pulls the AP database from the MM. It builds a list of APs that are incorrectly provisioned and runs the core process on them. This is how we get APs to have the correct name when the HLINK is assigned after the AP is deployed.
This process is limited to 20 APs per day.
Work order process
From earlyb:
The provisioning piece doesn’t talk to Atlas at all. There is a WAP inventory job that does talk to Atlas. I don’t remember exactly what that job does, but I think it generates a report of mismatches between the network and Atlas.
Limitations
Also from earlyb:
The only thing I can think of is that the provisioner is unable to talk to any controller that only has an IPv6 address. The docker swarm where it’s deployed apparently has some problem reaching those addresses. This may be resolved in the future when we shift where it’s deployed. Or maybe not.
Logs
- Currently in the ELK stack
log_aaa-*index- 1s precision, look at the timestamp in the log
instance.name:orca-job-prod_wap-provision-*fields.group: laa.nis.docker
Compromised user account
We occasionally get a request from ITSO to disable a user account and disconnect all associated network sessions. This is the procedure on how to do that for Wi-Fi sessions.
Find active sessions
Log into the mobility conductor (MC, previously called mobility master (MM)) via
ssh, and use the show global-user-table command:
(isb-mm-1) [mynode] #show global-user-table list name PID
Global Users
------------
IP MAC Name Current switch Role Auth AP name Roaming Essid Bssid Phy Profile Type User Type
---------- ------------ ------ -------------- ---- ---- ------- ------- ----- ----- --- ------- ---- ---------
2607:b400:24:0:1234:5678:9abc:def c6:ea:aa:11:22:33 PID@vt.edu 172.16.1.11 ur-vt 802.1x SQUIR-238BA1077Q Wireless eduroam 48:2f:6b:a3:35:40 2.4GHz-HE aaa-eduroam N/A WIRELESS
fe80::ab:cdef:123:4abc c6:ea:aa:11:22:33 PID@vt.edu 172.16.1.11 ur-vt 802.1x SQUIR-238BA1077Q Wireless eduroam 48:2f:6b:a3:35:40 2.4GHz-HE aaa-eduroam N/A WIRELESS
2607:b400:24:0:123:4567:89ab:cdef c6:ea:aa:11:22:33 PID@vt.edu 172.16.1.11 ur-vt 802.1x SQUIR-238BA1077Q Wireless eduroam 48:2f:6b:a3:35:40 2.4GHz-HE aaa-eduroam N/A WIRELESS
172.30.123.195 c6:ea:aa:11:22:33 PID@vt.edu 172.16.1.11 ur-vt 802.1x SQUIR-238BA1077Q Wireless eduroam 48:2f:6b:a3:35:40 2.4GHz-HE aaa-eduroam N/A WIRELESS
Total entries = 4
Searching by the PID will return results for both PID (e.g., registered
devices) and PID@vt.edu (e.g., eduroam).
Terminate the sessions
For each unique MAC address listed in the previous step, use the
aaa user delate command to end the sessions.
Note that deleting by the username from the MC is not currently supported.
(isb-mm-1) [mynode] #aaa user delete name PID
This command is not currently supported
(isb-mm-1) [mynode] #aaa user delete mac c6:ea:aa:11:22:33
Users will be deleted at MDs. Please check show CLI for the status
(isb-mm-1) [mynode] #show aaa user-delete-result
Summary of user delete CLI requests !
Current user delete request timeout value: 300 seconds
aaa user delete mac c6:ea:aa:11:22:33 , Overall Status- Response pending , Total users deleted- 0
MD IP : 172.16.1.11, Status- Complete , Count- 0
MD IP : 172.16.1.12, Status- Complete , Count- 0
MD IP : 172.16.1.13, Status- Complete , Count- 0
MD IP : 172.16.1.14, Status- Complete , Count- 0
MD IP : 172.16.1.141, Status- Complete , Count- 0
MD IP : 172.16.1.142, Status- Complete , Count- 0
MD IP : 172.16.1.143, Status- Complete , Count- 0
MD IP : 172.16.1.144, Status- Complete , Count- 0
MD IP : 172.17.1.11, Status- Complete , Count- 0
MD IP : 172.17.1.12, Status- Complete , Count- 0
MD IP : 172.17.1.13, Status- Complete , Count- 0
MD IP : 172.17.1.14, Status- Complete , Count- 0
MD IP : 0.0.0.0, Status- Response pending , Count- 0
MD IP : 0.0.0.0, Status- Response pending , Count- 0
MD IP : 172.16.236.151, Status- Complete , Count- 0
MD IP : 172.16.236.152, Status- Complete , Count- 0
You may notice in that example, the VTC controllers which are connecting over
IPv6 (shown as MD IP : 0.0.0.0) still have the response pending.
This seems to be a bug.
To work around this bug, log into the appropriate MDs (reference “Current
switch” column in the global users table) and run the same command.
(col-md-1) #aaa user delete mac c6:ea:aa:11:22:33
Enhancements
things we think we want to do
These are in no particular order. Small stuff listed below. Bigger items get their own pages (see left).
blacklist script
- update local script with
no ap ap-blacklist-timecommand - potentially work with devs to create orchestra app
Open Wireless Encryption (OWE)
- Tested as working on AP-225
- Not actually supported on AP-2xx
update clearpass to expect_owetm_prefix and_951c89easuffix- disable in VTC, due to high number of existing SSIDs
WPA3
On ArubaOS 8.10:
- On 2.4GHz and 5GHz:
- WPA SHA256 (AKM 5) does not work; opmode wpa3-aes-ccm-128 uses WPA (AKM 1)
- Protected Management Frames required (PMF-R) does not work with 802.11r (AKM 3)
- On 6GHz:
- opmde wpa3-aes-ccm-128 works as expected
- PMF-R is required On ArubaOS 8.11+:
- We can enable AKMs 1, 3, and 5 simultaneously on both bands
- PMF-R works with 802.11r
PAPI authentication
See ArubaOS 8.7.0.0 User Guide page 783.
EAP-TLS Project
Timeline
- Target completion: Summer 2026
- Add new CA to existing server cert chain
- Deploy on-boarding service
- Get dev eduroam instance running
- Pick an on-boarding option
- Finalize/create PKI
Things to check
- Does installing a custom CA for Wi-Fi mean the browser trusts the CA, too?
- Source
- Might be an issue for Windows and built-in browsers
- Certificate constraint “Extension: Extended Key Usage = TLS Web Server Authentication” might need to be set to make Windows (XP(‽) and above) happy.
Tasks
- Add new root to existing server cert chain
- Determine key type
- What do clients support?
- What does the onboarding tool support?
- What does the PKI infrastructure support?
- How do we create the USERTrust intermediate cert?
- Solved in openssl, assuming direct access to the new root’s private key
- Unknown how to do this in Vault
- Determine key type
Pre-project discussion
Timeline
- Target production date: Fall 2022
- Transition: Summer II - Fall 2022
- Maybe a transition period
- Maybe a transition point
- Onboard in service: Jan 2022
Transition options
Hard cutover
Dual profile
Dual auth
Draft of project scope
- Stake holders
- Major milestones
- Anticipated resources
- Budget
- What work needs set aside to get this done
External Resources
- Liberty University
- TJ Norton
- In process of switching to EAP-TLS
- Onboarding tool is SecureW2
- UNC (Ryan Turner)
blockers
- On boarding tool
- CA for users
- CA for auth server
Questions:
- Do we want on-boarding as a cloud SaaS?
- Do we care if the pki is in the cloud?
- Define what the cert actually asserts
- Creating a trust relationship between a device and the entity VT
- Associating a user/entity/org with that device
- Define a CPS
- Do we have a crl/ocsp? (prolly not)
- What attributes does the root CA need?
Endpoint management
We want to be able to integrate with:
- JAMF (macOS)
- InTune/AD (Windows)
- Bigfix
- macOS
- Windows
- Optional
Challenges
Certificate management
Something needs to issue the client and server certs. InCommon is ill suited for both. See the preproject page for more discussion.
Onboarding
A tool is needed to work well for BYOD and managed devices. These may not be the same tool.
Apple CNA
Apple uses a limited browser for captive portals. This can interfere with the profile provisioning tool.
Relevant educause discussion
On-boarding tool
Objective
On-board a device to the VT wireless network. This establishes trust that a device belongs to a particular entity (user or organization).
Necessity
#fn main() {
let project = 42;
let tool = Tool {
works: true,
easy: true,
};
if !(tool.works && tool.easy) {
drop(project);
}
else {
// println!("https://www.youtube.com/watch?v=ZXsQAXx_ao0");
println!("Let's go!");
}
#}
#struct Tool {
works: bool,
easy: bool,
#}Values
Roughly in order:
- Interoperable: cross-platform across all major platforms
- Usable: easy to use
- Robust: hard to get wrong
- Maintainable: easy to update to keep up with new demands
- Interoperable: integrate with other tools
- Supportable:
On-boarding Tool Requirements
These are the things we will be looking for in deciding on a tool. Obviously, cost is also a consideration.
MUST have
Tools that do not meet these criteria will not be considered. These are the things that we would rather not deploy EAP-TLS than compromise on.
front end
- Platform support
- Windows 10
- Windows 11
- macOS
- iOS
- Android
- including Android 11, December 2020 patch
- manual install (Linux devices)
- Easier to use than:
- non-sponsored guest (taking into account re-registering every day)
- Current PEAP/MSCHAPv2 process (with unknown password)
- SSO integration
- remove and/or replace old profiles
back end
- Per device certs
- Certs issued to:
- User
- Organization
- Setup correct trust of server
- Set specific CA
- Set leaf CommonName / subjectAltName
- Stupidly long client cert lifetime (e.g., 50 years)
- No cloud PKI
- Ability to expand to external CA
SHOULD have
We would rather deploy without these than not deploy, but we aren’t going to be happy about it.
front end
- Easier to use than:
- non-sponsored guest (not taking into account re-registering every day)
- Current PEAP/MSCHAPv2 process (with known password)
- vt.edu URL
back end
- Internal CA (with an intermediate root)
- ECC certs (P-256, or ed2519)
Low priority niceties
Extras that in particular will make future expansions of the service better.
- Passpoint support
- AD integration
- Multiple root CA support
- ed25519 support
Contenders
SecureW2
Based on feedback from peers, this is the most likely candidate. It works well and is a reasonable cost.
ClearPass Onboard
Again, based on the feedback of peers, this seems to be an excellent product, possibly better then SecureW2, but is very expensive. Even the vendor admits that it is priced too high.
Nonetheless, given we already have a CPPM instance running, it is worth taking a look at it.
Honorable mentions
eduroamCAT and geteduroam
Notably, it does not seem to support macOS[^1], which makes it a non-starter.
Open-source, community-driven project, with all the good and bad that comes with that. It would definitely be more effort to setup, probably more than we care to do.
Links:
Ruckus XpressConnect
Notably, we used to run XpressConnect before ditching it in favor of… nothing (with eduroamCAT as a backup). It is not likely that we are going to move back to it.
Sectigo Mobile Certificate Manager
Middleware is considering this as an option for an internal CA. It appears to have a certificate provisioning component as well.
Concerns:
- Middleware seems o be leaning toward using AWS as CA service.
- It seems prudent to not tie the on-boarding tool to the CA we are using.
- It is not clear if this will work for non-mobile platforms (e.g., Windows, macOS)
Reference [pdf][secitgo].
Authentication
Auth from a cloud service?
No. Right now our cloud exit strategy is “don’t exit”. The ongoing cost to maintain the eduroam authentication service is fantastically little. This makes the tradeoff between up-front engineer time and a perpetual bill from a service provider (not to mention a soft vendor lock in).
ArubaOS 10 / controller LCM
Nomenclature note: in ArubaOS 10, “MDs” become “mobility gateways” or simply “gateways” for short.
AOS 8 requirements:
At a minimum, we need ten (10) 9240s on campus.
- 9240s (with a gold license) can handle the same number of APs/clients as 7240s
on AOS 8.
- 2k APs
- 32k clients
- With 8800 APs on campus, we at a minimum 5 controllers online for all the APs to be up. Double that for all APs to have a standby tunnel built.
AOS 10 requirements:
We need 8 total 9240s.
- Campus: 4x (gold license)
- equinix: 2x (base hardware)
- vtc: 2x (base hardware)
Reasoning:
- A single 9240 (with gold license) can handle:
- 16k APs
- 64k clients
- With 2 gateways in each switchroom (bur/col), we can lose a whole switch room (power, meteor, whatever) and have all the APs still be up with a redundant connection.
- Why not 1 gateway per switchroom?
- client count would be tight in a failure scenario
- a failure of any kind leaves us without any redundancy
- we’ll already have the hardware (which is relatively cheap to begin with) due to AOS 8 requirements
- For off campus locations (equinix/vtc), we just need redundancy.
Migration plan
Phase 1 (AOS 8):
- License them all with a gold license
- Deploy them on EVPN
- bur: 5
- col: 5
- cluster configured with two groups, so each AP has their AAC/S-AAC to distinct switch rooms.
- Move campus APs to the new 10 node cluster
- Use campus 7240XMs for dev/pprd
- probably leave the col/bur MDs in place for phase 2 (though we will need to move fiber to connect them to EVPN)
Phase 2 (start moving APs to AOS 10):
- Setup at least 4 7240XMs on EVPN with AOS 10
- probably 2 each in bur/col
- exact number and placement subject to future consideration
- Migrate at least 3k APs to AOS 10 cluster
- This will certainly be done in stages and after lots of dev/testing, etc
- We need few enough APs on the AOS 8 cluster to be able to remove 4 controllers. This leaves us with 6x 9240s, which can handle 6k APs.
Phase 3 (campus 9240s to AOS 10):
- Remove 4 9240s from the AOS 8 cluster and add them to the AOS 10 cluster
- Remove 7240XMs from AOS 10 cluster
- Move the rest of campus to the new AOS 10 cluster
- Optionally consolidate fiber links so the gateways are connected at 4x 25G
- We should have plenty of links left over from consolidating the cluster from 10 MDs to 4 gateways.
Phase 4 (remote locations):
- Downgrade license on remaining 4 9240s to base hardware
- Use 4 now empty 9240s for VTC and equinix (AOS 10)
- Use remaining 2 9240s in dev
Bonus Phase (stadium):
- Use dev 9240s in the stadium (upgrade license to gold)
- Buy 9000 series (or use VMs) for dev/pprd
IPv6
The goal is to be able to remove any legacy IP address from the mobility infrastructure.
Until Central on Prem is able to use IPv6, the controllers (MCs and MDs) will need a legacy address. It is possible that a multicast discovery service (e.g., airgroup) will also need a legacy address on the client networks.
Current status
| bur | col | res | eqx | vtc | |
|---|---|---|---|---|---|
| dns | 4 | 4 | 4 | 4,6 | 4,6 |
| ntp | 4 | 4 | 4 | 4,6 | 4,6 |
| syslog (akips) | 4 | 4 | 4 | 6 | 6 |
| syslog (central) | 4 | 4 | 4 | 4 | 4 |
| snmp traps | 4 | 4 | 4 | 6 | 6 |
| cppm auth | 4 | 4 | 4 | 4 | 4 |
| user interface (bfv) | 4 | 4 | 4,6 | ∅ | 4,6 |
| user interface (guest) | 4,6 | 4,6 | 4,6 | ∅ | 4,6 |
| mgmt interface | 4,6 | 4,6 | 4,6 | 4,6 | 4,6 |
| cluster (md-md) | 4 | 4 | 4 | 4 | 4 |
mm-md (masterip cmd, ipsec tunnel) | 4 | 4 | 4 | 6 | 6 |
| AP | 4 | 4 | 4 | 4 | 4 |
Quarantine
Currently, if we need to prevent a device from connecting, it is blocked by MAC address on the controller.
The device registration LDAP includes a prohibited field, which is used during
authorization.
Any device connecting with a banned MAC is placed in the unauthenticated
network, irrespective of registration, and is put behind a captive portal.
This captive portal will be a static page without a network login. Instead, it will display a message saying the device has been blocked and that the user should contact 4Help.
Post-Mortem
Motivation
The primary goal of the out-of-band (OOB) management network is that the devices are remotely manageable in the case of disaster, when the rest of the network is not functional, and thus service can be restored.
The secondary goal/benefit of the OOB management network is for security. Isolating management to only the OOB network significantly reduces the attack surface of the equipment.
Counter motivation
The first goal is irrelevant, because the Wi-Fi network is an overlay. If the equipment is not reachable it is because the underlay is not working, and we’ll be fixing that first. Two notes here:
- Administrators of the Wi-Fi network need some kind of network connectivity that isn’t the VT Wi-Fi network, which is trivial. A wired adapter, home ISP, mobile hotspot, any of these will do.
- To address the case of a device with an unusable network configuration (e.g., the out of box config), they still need some kind of non-network access (i.e., serial), though that access can be reachable through network resources. Indeed, serial connection accessed through the OOB network is already part of our standard setup.
The second goal strongly implies (though doesn’t strictly require) that the management of a device is isolated to that device. This is not the case with the Wi-Fi infrastructure. The configuration is all done on the MC, which is pushed to the MDs, which is in turn pushed to the APs.
More critically, there is a need for the management to have a clear separation from the production and support network. An overlay design does not lend itself to this, and sure enough, it does not exist in the wireless controllers. In particular, the controllers do not have multiple routing tables, which makes it extremely difficult if not impossible to separate the different network planes.
In particular:
- user traffic is carried to the MD inside a tunnel
- MDs in a cluster build a tunnel and have a host specific route to each other
- MDs build a tunnel and have a host specific route the MCs
This means any wireless user can reach† the management of the MC any MD in the cluster they are connected to. This could be stopped with a client ACL, but it must:
- be applied to every role
- enumerate every address (including IPv6 link local!) on every controller
This is obviously error prone and a fair bit of work, all to accomplish a secondary goal. And we still end with a design that is only a weak assurance of this goal (e.g., have we found every path into the management plane? Probably not.)
† Can reach the L4 management interface that is. Obviously, L7 still needs auth(z).
Out-Of-Band Management
Logical Diagram

Data paths
- MD join clusters with the in band management address
lc-cluster group-profile "lcc-foo" controller-v6 <blue> priority 255 mcast-vlan 0 vrrp-ip-v6 <blue> vrrp-vlan <blue> group <#> - APs connect to cluster on in band management
- In band mgmt and user networks are trunked over the same port channel.
- MD controller IP is in band mgmt
masteripv6 ... interface-f vlan-f <blue> ... controller-ipv6 vlan <blue> address <blue> - mgmt auth (i.e., netadmin) for MDs happens on OOB mgmt
- user auth (e.g., eduroam) happens on in band mgmt
- MC-MD management happens inside the IPsec tunnel that gets built over the in band management.
Questions
- How do we prevent mgmt login from non-OOB mgmt
networks?
If we can’t do this, we haven’t actually done anything.
- Force management to ports
22and4343, and only allow these on OOB- AP-MD and MD-MC management is done through a tunnel, thus not stopped by these ACLs. This is good for the purposes of getting things to work, but kinda violates the principles we are after to begin with.
- Captive portals use ports
80and443and we can force HTTPS management to exclusively4343. This lets us expose a L7 distinction in L4. Again, this functions, but eww.
- Force management to ports
- How many captive portal users are legacy only? Do we need this legacy address?
- Can we do no legacy addresses?
- No. At the least, we need legacy addresses for RAPs.
- Can we add members to a cluster by an IP that is not the controller IP?
- Yes
- Do we want to keep a legacy address on in band mgmt
to give us time to migrate APs? (And to have less changes at once)
- Yes. Lets make less changes at once.
TODO
conehead/grub
- Add v6 addresses on the OOB mgmt [NISNETR-396]
- Accept netadmin auth from the MDs’ oob mgmt [NISNETR-399]
MM
Nothing?
MD
- Wire up MDs on OOB
- Address MDs on OOB
- Apply static route to OOB network
- Apply ACLs to limit port 4343 and 22 to only be allowed on the OOB side [NISNETR-398]
- Change
asr-conehead-netadminto use the OOB v6 address on conehead [NISNETR-399] - Change
asr-grub-netadminto use the OOB v6 address on grub [NISNETR-399] - Figure out initial setup
- Remove remaining legacy addresses
Config changes
The MM is configured exactly the same as before. The MDs have additional configuration (col-md-5.dev as an example here):
interface gigabitethernet 0/0/0
no shutdown
!
vlan 301
description oob-mgmt
!
interface port-channel 1
gigabitethernet 0/0/0
switchport access vlan 301
switchport mode access
trusted
trusted vlan 1-4094
!
interface vlan 301
operstate up
ipv6 address 2607:b400:e1:4000:0:0:0:15/64
!
ipv6 route 2607:b400:e1:0:0:0:0:0/48 2607:b400:e1:4000:0:0:132:1
Old ideas
These are things we are currently deciding against. They are noted here in case they turn out to be a good idea or lead to other useful ideas.
MC-MD connection:
- Static routes over OOB
- IPsec tunnel between MC and FW
Remote APs
Overview
Also known as a RAP.
Steps:
- RAP IP pool on
/mm - Public addresses
- DNS
- Cluster
IP Pool
The RAPs use an IP address inside the IPSec tunnel. The scope of this address is limited to the AP and MD, which makes it a good candidate for link local addressing. Each RAP uses 1 address, so make sure the pool has at least as many addresses as there are RAPs.
It is configured as a lc-rap-pool at /mm.
By convention, we use the prefix rapp-.
CLI
Configure (at /mm):
lc-rap-pool rapp-rap 169.254.10.10 169.254.10.50
Verify:
(isb-mm-1) [mm] #show lc-rap-pool
IP addresses used in pool rapp-rap
169.254.10.10-169.254.10.21
IPv4 pool : Total - 12 IPs used - 29 IPs free - 41 IPs configured
IPv6 pool : Total - 0 IPs used - 0 IPs free - 0 IPs configured
LC RAP Pool Total Allocs/Deallocs/Reserves : 13/0/0
LC RAP Pool Allocs/Deallocs/Reserves(succ/fail) : 12/0/(0/0)
API
Config:
{
"lc_rap_pool":[
{
"pool_end_address": "169.254.10.50",
"pool_name": "rapp-rap",
"pool_start_address": "169.254.10.10"
}
]
}
Running the show command via API does not return (meaningfully) structured
data (last tested on AOS 8.7.1.2).
Public addresses
The key requirement is n public legacy (IPv4) addresses for n controllers in the cluster.
Documentation suggests that the public address could exist on a NAT device.
We’ve opted to set it up directly on the MD.
This is done just like any other vlan interface.
It doesn’t make any sense to use IPv6 with the RAP service.
- If we knew we had IPv6 connectivity from the remote location, we could just setup the AP as a campus AP (CAP) with CPSec. Improved RAP discovery with Aruba Activate may be a compelling reason to go with a RAP anyways. We haven’t yet gotten that far with the RAP setup, though.
- Too many ISPs still offer legacy-only connectivity.
Also, RAPs cannot use a VRRP address to connect to the cluster, so don’t bother setting up an AP discovery VIP.
DNS
- RAPs must look for the MDs by DNS (since VRRP isn’t an option)
- VT uses the address
rap.mobility.nis.vt.edu - This name must resolve to each of the public addresses of the MDs in the cluster.
- The MDs take care of load balancing once the RAP has connected, so any method DNS uses (round-robin, ordered list, etc) is fine.
$ dig +short rap.mobility.nis.vt.edu
198.82.171.142
198.82.171.141
Cluster
The only extra step here is to provide the RAP external IP.
Remember to follow the usual clustering steps as well (vlan excludes, join the md to the cluster, etc)
CLI
(isb-mm-1) [rap] #show configuration committed | begin lcc-
lc-cluster group-profile "lcc-col-rap"
controller 172.16.1.31 priority 255 mcast-vlan 299 vrrp-ip 172.16.1.41 vrrp-vlan 299 group 0 rap-public-ip 198.82.171.141
controller 172.16.1.32 priority 128 mcast-vlan 299 vrrp-ip 172.16.1.42 vrrp-vlan 299 group 0 rap-public-ip 198.82.171.142
!
API
{
"cluster_prof": [
{
"cluster_controller": [
{
"group_id": 0,
"ip": "172.16.1.31",
"mcast_vlan": 299,
"prio": 255,
"rap_public_ip": "198.82.171.141",
"vrrp_ip": "172.16.1.41",
"vrrp_vlan": 299
},
{
"group_id": 0,
"ip": "172.16.1.32",
"mcast_vlan": 299,
"prio": 255,
"rap_public_ip": "198.82.171.142",
"vrrp_ip": "172.16.1.42",
"vrrp_vlan": 299
}
],
"profile-name": "lcc-col-rap",
"vrrp_info": {
"vrrp_id": 240,
"vrrp_passphrase": ""
}
}
]
}
Monitoring
Ignore the colors. Splunk picks the colors, so red might mean accept or some other nonsense. Make sure you look at the legend.
eduroam
Row 1
- Overall distribution of requests.
- This is sourced from the authentication servers.
- Time selected from the “Recent time” picker.
Row 2
- Outcome ratios broken down by cluster
- Sourced from the authentication servers (FreeRADIUS).
- Time selected from the “Recent time” picker.
- Timestamps of these logs are based on when the server has a response prepared to send, not when it is actually sent. Notably, rejects get a 1s delay (by design).
Row 3
- Outcome ratios broken down by cluster.
- Sourced from the controllers.
- Time selected from the “Recent time” picker.
- A reject log is generated from the
dot1x-procprocess. - An accept log is generated from the
authmgrprocess.- log generated when an entry is added to the user table
- log per IP address, not per authentication request.
- Typically 3-4 times as many accepts compared to row 2.
- A device that gets an accept, but is unable to get an IP address is not logged from the controller’s perspective.
Row 4
- Top talkers
- Sourced from the authentication servers.
- Time selected from the “Top time” picker.
ClearPass (CPPM)
- Due to MAC auth, it is normal for there to be far more rejects than accepts.
- Extraordinarily few rejects are actually sent. Instead devices are “rejected” by not assigning a role.
- Web auth happens after the user gets an IP address.
Left column
- Outcome ratios broken down by cluster.
- Sourced from the controllers.
Right column
- Outcome ratios broken down by cluster.
- Sourced from the authentication servers (CPPM).
- For more details on recent events, check the access tracker in CPPM.
Export CPPM guest accounts (cppm 6.6)
This is all done from the Guest side of CPPM.
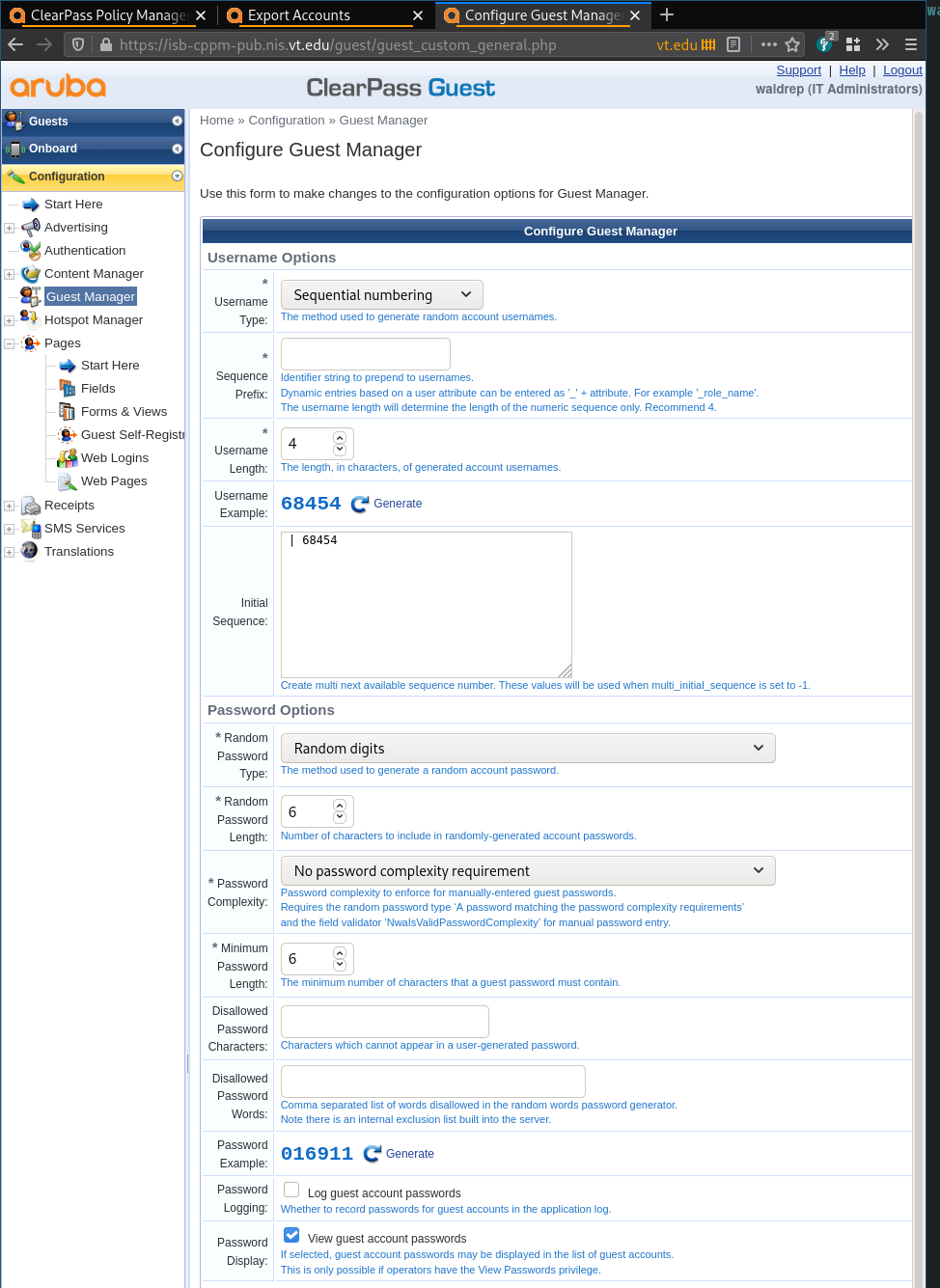
Enable viewing passwords
- Go to Configuration > Guest Manager
- Enable the ‘Password Display’ option to view guest account passwords.
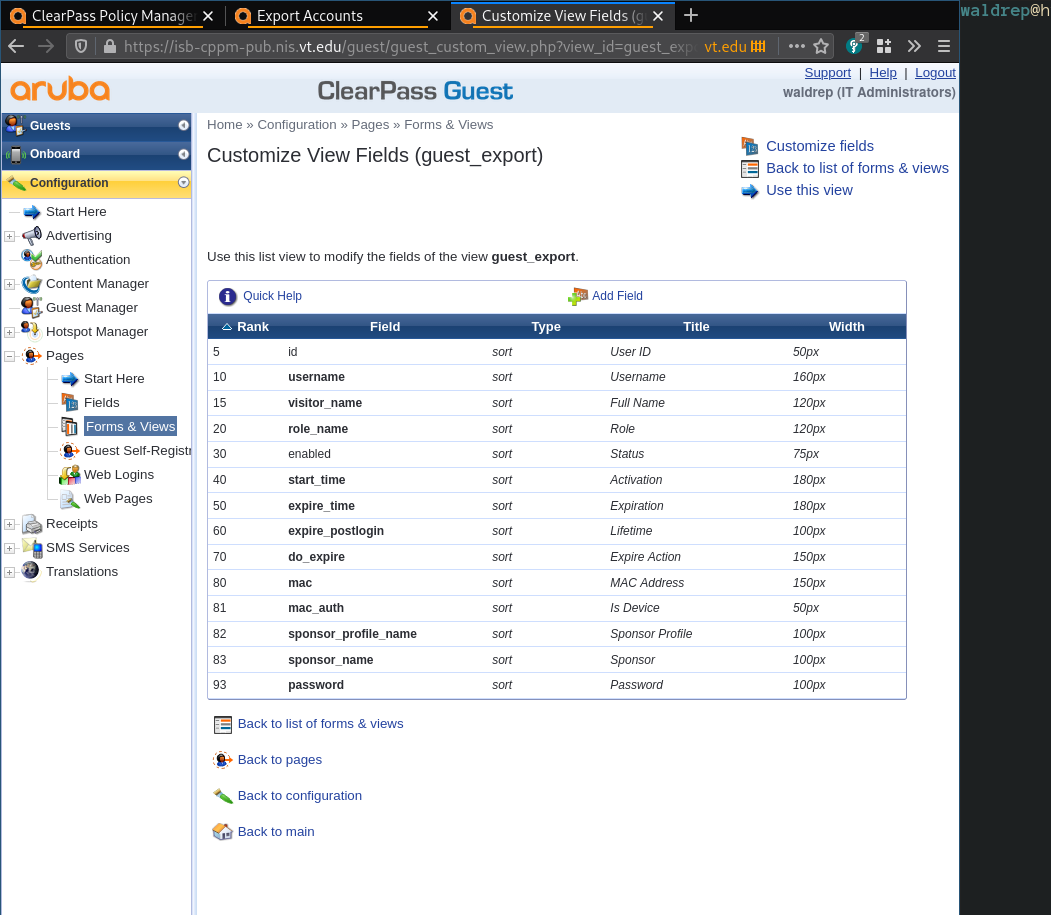
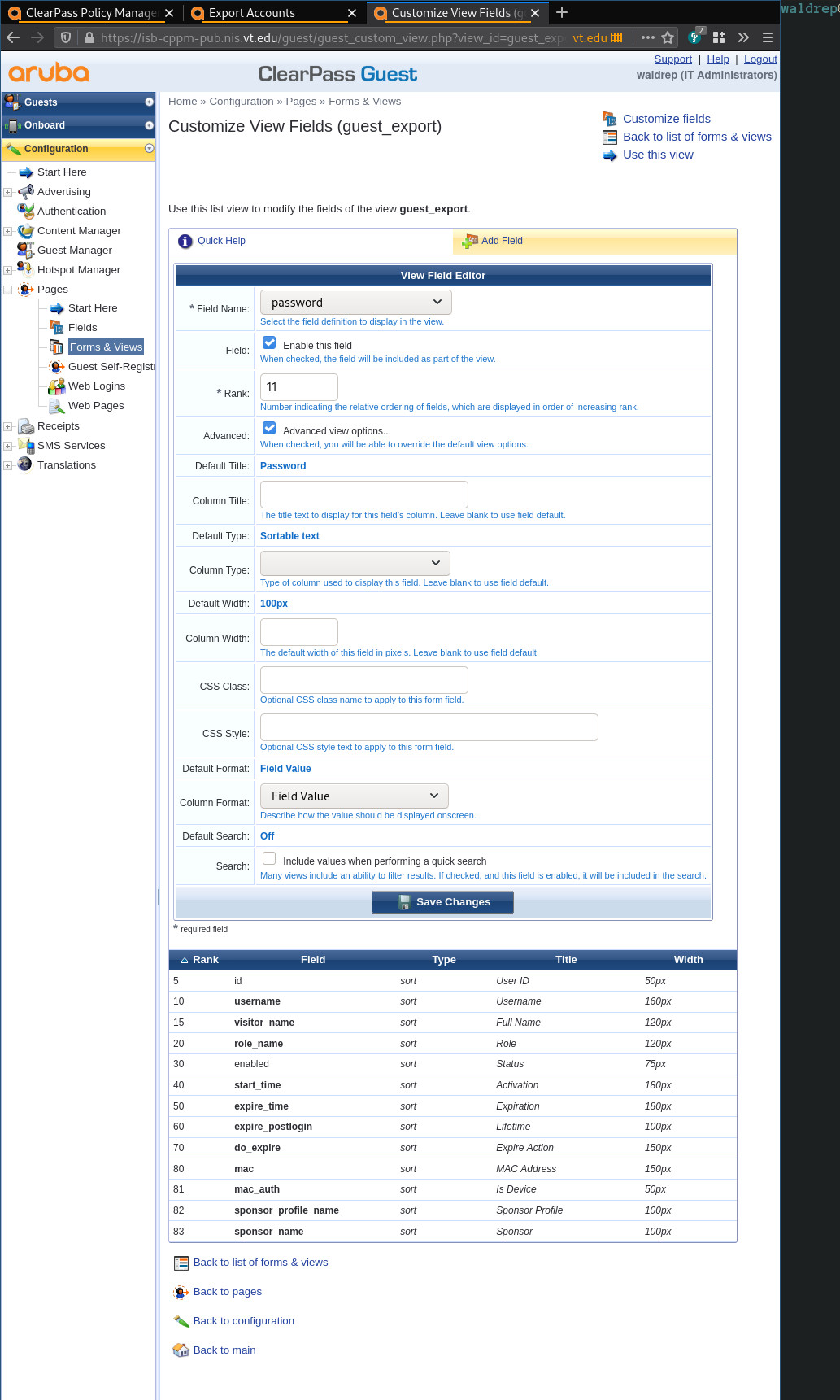
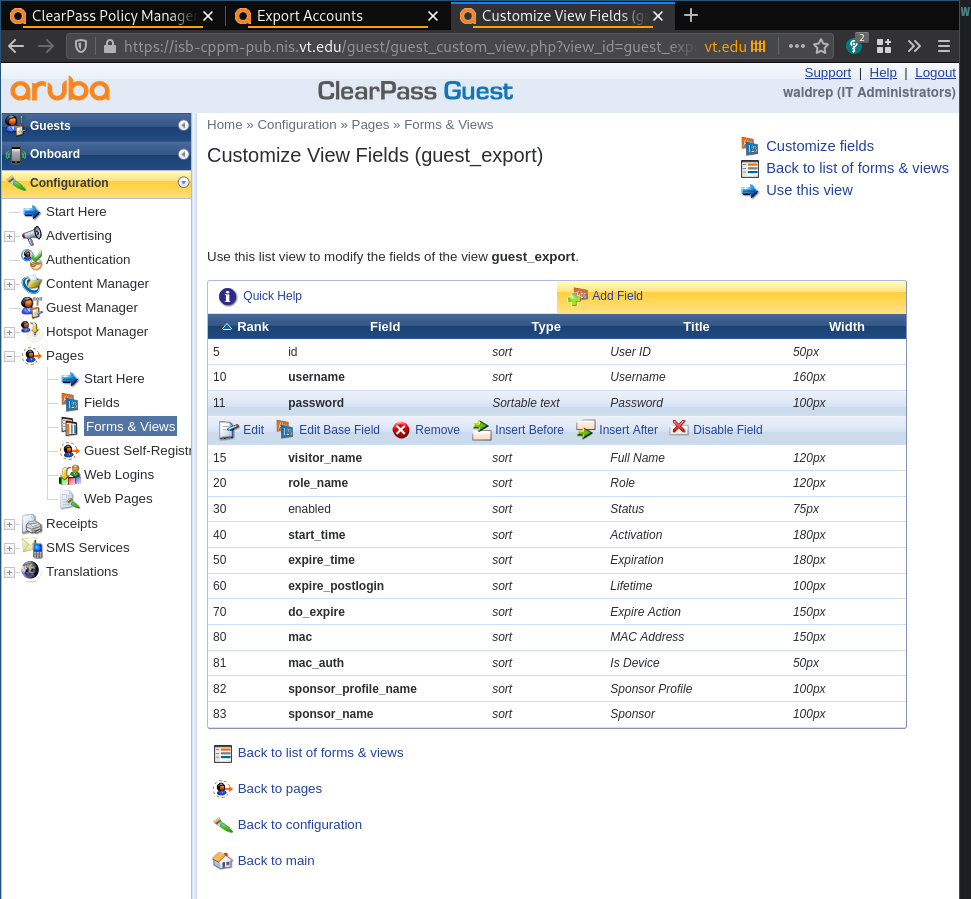
Customize default export view
- Go to Guests > Export Accounts > Customize default export view
- Look for the field
passwordin the list. If it is not there, click ‘Add Field’. - In the “Field Name” drop box, select “password”.
- Optionally, set the “Rank”
- Save Changes
- Use this view
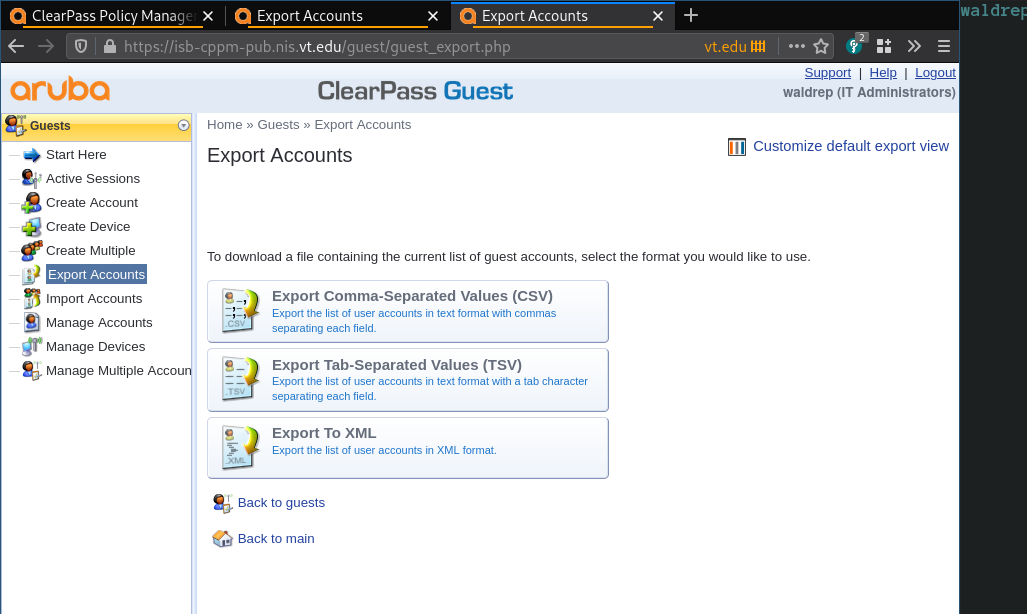
Export the data
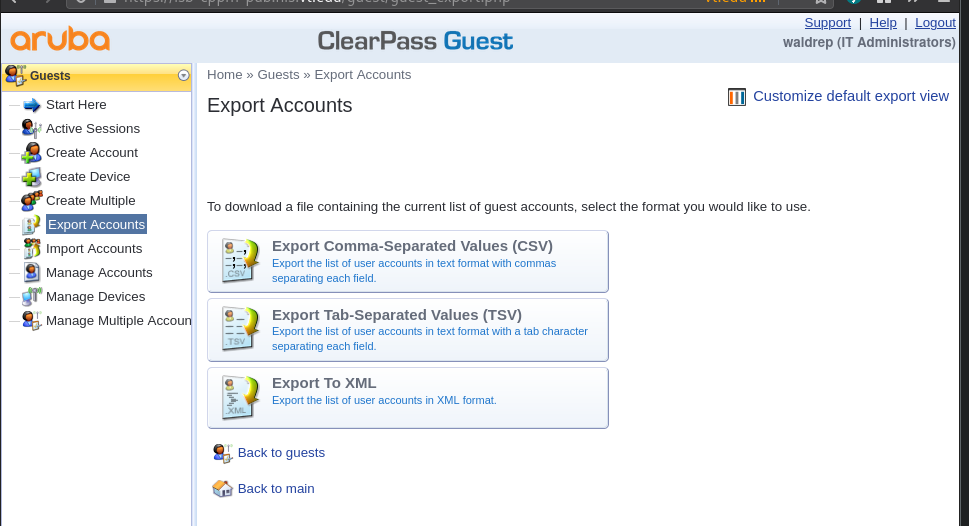
- On export page (Guests > Export Accounts), select what kind of export you want and save the file.
Unsorted images of the process
Factory reset CPPM
Everything is from the serial console, logged in as appadmin.
Save licensing info
[appadmin@cppm]# show license
-------------------------------------------------------
Application : ClearPassPlatform
License key : -----BEGIN CLEARPASS PLATFORM LICENSE KEY-----
[snip!]
-----END CLEARPASS PLATFORM LICENSE KEY-----
License key type : Permanent
License added on : 2022-03-08 18:55:04
Validity : <not applicable>
Customer id : [snip!]
Licensed features : <not applicable>
=======================================================
The license key may look like a base64 encoding with a header/footer like above, or it might be formatted similar to a Windows license key.
Whatever the case, grab all the output and keep it somewhere safe.
Wipe the database
[appadmin@cppm]# cluster reset-database -f
The -f option (think --force) will wipe any local IP entries in the
database, as well as licensing.
Reset and Reboot
[appadmin@cppm]# system factory-reset
According to TAC, this does something close to resetting the database without
-f.
Notably, it also reboots the box and takes you to the initial setup wizard, so
it is probably a good starting place.
Note that after the reboot, the login screen may display a message about upgrading and to not make any config changes. Press Enter occasionally until that message no longer shows before starting. It will take several minutes.
Guidelines
This is a collection of the less technical side of things. Policies, procedures, conventions, and the like are all collected here.
Administrator Access
Credentials
Password authentication is handled through:
- netadmin RADIUS instance
- single local account for backup
Key authentication is handled through:
- local accounts
Roles
- ArubaOS:
- There is a predefined, uneditable list of roles.
- Local accounts cannot be created without a role.
- RADIUS accounts set the role with
Aruba-Admin-RoleVSA.- If the VSA is missing, then a default role is applied.
- The default role is set in the “Management Authentication Profile”.
- Absence of config default is
root - API:
.mgmt_auth_profile.mgmt_default_role.aaa_auth_mgmt_default_role - CLI:
aaa authentication mgmt default-role
- If the VSA is invalid, access is denied.
- If the VSA is missing, then a default role is applied.
- Airwave:
- Roles can be created and edited.
- Local accounts cannot be created without a role.
- A RADIUS account uses the
Arbua-Admin-RoleVSA (same as ArubaOS).- If the VSA is missing, access is denied.
- If the VSA is invalid, access is denied.
netadmin accounts
Role config:
- The default role is set to
read-onlyat the highest possible nodes.
Rational:- Damage control in the case of a misconfigured RADIUS account or ArubaOS behavior change.
- All controllers are descendants of these two nodes.
- All RADIUS accounts must have the
Aruba-Admin-Roleset.
Rational:- Implicit authorization is confusing and makes it easy to miss mistakes.
- Accounts that should not have access to the wireless controllers should user
the value
deny, or a role that is exclusive to AirWave.
Rational:- Not all netadmin accounts should have controller access.
- Some users need access to AirWave, but not the controllers.
- A bogus value is the only way to deny access to a netadmin account.
- A consistent, clear value makes for easy auditing.
Who:
- Members of the Network Engineering and Operations (NEO) team have full access.
- Support staff may have read-only access.
- This is approved by the wireless team lead or Network Operations Manager. Verbal approval is fine.
- Automation has the least access possible for its tasks.
Local accounts
Config:
To view local users via API, check:
.mgmt_user_cfg_int.mgmt_user_ssh_pubkey.mgmt_user_web_cacert
Or from the command line:
show mgmt-usershow mgmt-user ssh-pubkeyshow mgmt-user webui-cacert
Note that each of these lists partition1 the local users.
That is show mgmt-user will not show users with ssh pubkey access.
admin user
This account can be created while setting up a controller. We opt to do so, as it eases the painful process of setting up an MD.
If the account is created on setup:
- The username is
admin. - The password is set by the engineer.
- ArubaOS doesn’t give a choice on either of these.
The account is created at the device level of the config hierarchy, so it overrides any other config that may be set. This creates a management headache, so we opt to remove the account after the MD connects to the MM.
The account on the MMs is a special case. Aruba, in their infinite wisdom, does not allow it to be deleted, nor the role changed. We opt to set a randomly generated password and throw it away. This effectively disables the account.
nis user
- This account is the backup in case network connectivity is lost.
Rational:
- Entropy happens
- It is configured at the highest possible nodes.
Rational:- Entropy happens
- Centralized config makes for easy password changes
- Role is
root.
Rational:- Full access is required to make network config changes
Server settings
Telnet
Telnet is awful and is rightfully disabled by default. We leave it disabled. Unfortunately, verifying it is still disabled is a little tricky. This config is not part of the JSON that can be retrieved from the API. Instead we must either:
- run the
show configurationcommand from ssh (not the API) for each node - run
show telneton each device directly (either ssh or API).
To do the latter with the python library, do something like:
mm = arubaos.MobilityMaster(f"isb-mm.{domain}", creds)
for host in [md.name for md in mm.mds()]:
arubaos.Controller(f"{host}.{domain}", creds).show("telnet")["_data"]
Don’t forget to check both MMs as well.
SSH
The issues that are actual exploits in the wild are not able to be configured incorrectly. There are a few knobs that are closer to theoretical weaknesses that we opt to tighten up:
- DSA < RSA
- CBC < CTR
- SHA1 < SHA256 (used in an HMAC; when used for signing, it is more serious)
In the API:
{
"aaa_ssh_cipher": {
"cipher_suite": "aes-cbc"
},
"aaa_ssh_mac": {
"hmac-sha1": true,
"hmac-sha1-96": true
}
}
Again, we find that disabling DSA (.aaa_ssh_dsa) is missing from the config
pulled via API.
Audit trail
Commands run on the controllers, via SSH or API, can be found with the Splunk report ArubaOS command audit.
-
Using the set theory definition of the word here ↩
Upgrades
Procedure
All production upgrades MUST be documented in the Engineering Change Order (ECO) app (or its replacement), and follow the normal ECO procedure.
All upgrades should be tested in the dev environment before pushing to production.
When to upgrade
ArubaOS upgrades do not occur on a regular schedule. Rather, they are as an as needed or as available basis. Several things can motivate an upgrade. Roughly in order of priority:
- Security fixes
- Stability fixes
- New features
- Incremental update available
The rational for security and stability are obviously the top priority when providing a network service. Similarly, new features allow us to provide a better or new services.
When there is a security upgrade, the system should be upgraded ASAP; target within the week. Of course, this depends on the severity of the vulnerability. For example, a CVE score of 9+ may motivate an upgrade outside the normal change window to expedite the fix. A CVE score of 3 may wait until after a maintenance restriction window (such as due to semester startup or finals).
Stability fixes should be implemented in the next change window or two, pending testing of the code.
New features can wait the longest before role out. It is more important that the system be stable and predictable than have the shiniest new feature.
Incremental updates should be implemented in 10 days of release, but not during a maintenance restriction.
What to upgrade to
Staying on the latest release within a code train has allowed us to be patched against security vulnerabilities before they are announced. When we lag behind, we have hit stability bugs that are already fixed in newer releases.
Aruba has two public release types: “Standard” and “Conservative”. The conservative release is the more stable of the two.
At the time of this writing, we are on the 8.7 train, which is a standard release. It has a few key features:
- AP support
- RAP 500 series
- AP 560 series
- IPv6
- MM/MD connection
- clustering
- AirWave
Conservative release
This is the generally preferred release. Unless there there are known issues with the newer version, always go to the latest version.
Standard release
If we are already on a standard release (such as the time of this writing), stay within the same major/minor version (e.g., 8.7.0.1 to 8.7.1.2 is good).
Bugs
This is a way to keep track of bugs that we have come across.
Create a section in prework when we notice it. This provides a way to start keeping track of trends and not lose info, especially for issues that are not urgent enough to address right away.
When we start working on it in earnest (open a TAC case, create a JIRA ticket, etc), move that section to outstanding.
When the issue is resolved, move it to resolved.
If we work around an issue without resolving it, move it to workaround.
Outstanding
Controller IPv6 traffic stops
- Description: All IPv6 traffic to/from the controller itself ceases. This does not impact user traffic.
- Detection:
- The MD is reachable over IPv4, but not IPv6.
- The MD is unable to ping its IPv6 gateway.
- If the MD has established sessions (e.g., tunnels) to IPv6 addresses, those may continue to work.
- IPv6 neighbor table is stuck. It neither adds nor removes items dynamically.
- AKiPS availability
- AKiPS status
- Workaround:
- IPv6 dependencies have been (mostly?) removed. User impact should be minimal to none at this point. See Enhancements/IPv6 for details.
Bounce the link to the impacted controller. This can be done from either the controller or the router side. Additionally, it seems we can take down a single link in the port channel and bring it back up. Usually the link needs to stay down for a few seconds.- While the above does (temporarily) restore IPv6, it seems the failover mechanisms are broken, meaning the workaround is user impacting. Current practice is to leave IPv6 broken.
- Add a static neighbor entry:
This allows traffic to flow through the gateway, but does not allow traffic from the gateway itself.(isb-mm-1) [00:1a:1e:03:03:08] #show configuration committed | include neigh ipv6 neighbor 2607:b400:64:4000::1 vlan 299 00:31:46:17:df:f0(col-md-2) *#show ipv6 route Thu Jan 18 12:52:18.483 2024 Codes: C - connected, O - OSPF, R - RIP, S - static M - mgmt, U - route usable, * - candidate default Gateway of last resort is 2607:b400:64:4000::1 to network ::/128 at cost 1 S* ::/0 [0/1] via 2607:b400:64:4000::1* C 2607:b400:64:4000::/64 is directly connected, VLAN299 C 2607:b400:a00:1::/64 is directly connected, VLAN801 (col-md-2) *#ping ipv6 2001:468:c80:210f:0:165:9b7d:7dcb Press 'q' to abort. Sending 5, 92-byte ICMPv6 Echos to 2001:468:c80:210f:0:165:9b7d:7dcb, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 0.468/0.5676/0.656 ms (col-md-2) *#ping ipv6 2607:b400:64:4000::1 Press 'q' to abort. Sending 5, 92-byte ICMPv6 Echos to 2607:b400:64:4000::1, timeout is 2 seconds: ..... Success rate is 0 percent (0/5)
- Impact:
All communication between the controllers and CPPM is over v6. Thus, no clients can authenticate on theVirginiaTechSSID.Other system services on the controller happen over v6 including NTP and DNS.- Whatever the impact of an out-of-date neighbor table is.
- Unknowns / next steps:
- What is the impact of an incorrect neighbor table on an MD? E.g., what is the impact on a client that is not in the table? Does this impact Air Group? Efficiency/speed the MD can switch packets? Does this prevent the MD from short-circuiting or optimizing client ND?
- Is the MD participating in neighbor discovery at all? Is it sending/receiving NS? Is it sending NA?
- TAC cases:
Config out of sync
-
Description: The config on the MC device node and on the corresponding MD are different.
-
Symptoms From the MM:
(isb-mm-1) *[00:1a:1e:02:d8:90] #show configuration effective | include debugging logging user-debug 9c:b6:d0:da:1e:8f level debugging logging arm-user-debug 9c:b6:d0:da:1e:8f level debugging (isb-mm-1) *[00:1a:1e:02:d8:90] #From the MD:
(col-md-1) *#show running-config | include debugging Building Configuration... logging security process dot1x-proc level debugging logging level debugging arm-user-debug 9c:b6:d0:da:1e:8f logging level debugging user-debug 9c:b6:d0:da:1e:8f -
TAC case:
5360416723 -
Notes
ccm-debug full-config-syncdid not resolve the issue- Problem went away on it’s own, probably from subsequent commits.
- Currently writing a script that compares the config from API
Resolved
Connectivity failures (Aruba Support Advisory ARUBA-SA-20210901-PLVL04)
-
Description: Clients have association failures.
This case morphed into the Linux client issue. Linux clients would occasionally just stop passing traffic. The device would still be associated, but it could not even ping the UAC. It was mostly observed on Intel AX200 and AX210 cards, but has also been seen on Intel’s AC cards and the MediaTek MT7921K. The problem looked like a driver / kernel issue, but its disappearance is more closely correlated to upgrading to ArubaOS 8.10.
-
Symptoms:
- Clients experience association failures during high bursts of client roaming events.
- High CPU utilization by the Station Management process (
stm) in the MDs. show papi kernel-socket-stats | include 8345,8222,8419,DropsDropsvalue onport 8419 (STM Low Priority)rapidly increases in 100+ increments within seconds AND sustained large values forCurRxQLenandDrops on port 8435 (STM),
show cpuload currentstmprocess stays over 100%
-
TAC cases:
-
Notable versions:
- 8.7.1.4: observed
- 8.7.1.5: observed
- 8.7.1.6: Sanjay claims a fix
- 8.7.1.6: observed
- 8.10.0.6: presumed fixed
-
Debug: Logs requested by Rodger: Make sure user debug is enabled:
logging user-debug <client-mac> level debugCurrently enabled for waldrep’s laptop (46:96:f1:03:32:98)
no paging show cli-timestamp show clock show ap association client-mac <client-mac> show station-table | include <client-mac> show auth-tracebuf mac <client-mac> show ap client trail-info <client-mac> show datapath session table | include <ip address of client> show log user-debug 50 | include <client-mac> show log security 50 | include <client-mac> show log system 50 | include <Affected_AP_Name> tar log tech-supportCollect the following when at the time of the issue along with tech support logs:
clock cli-timestamp show dot1x watermark history show papi kernelpsocket-stats show ap debug client-mgmt-counters show ap debug sta-msg-stats show ap debug cluster-counters show ap debug gsm-counters show ap debug client-deauth-reason-counters show cpuload current show datapath bwm table show datapath utilization show datapath papi counters show datapath debug opcode show datapath network ingress show datapath maintenance counters show datapath debug dma counters show datapath message-queue counters show auth-tracebuf
Kernel panics
- Description: MD crashes with a kernel panic
- Symptoms
- MD reboots
- Kernel panic
- TAC asked for kernel core dumps. This option has been enabled for a while, but doesn’t seem to be giving what they are asking for.
- Intent:cause:registers:
12:86:b0:212:86:b0:412:86:e0:212:86:e0:412:86:e0:878:86:50:2(logs lost)
- Bug IDs
- AOS-216744
- TAC cases:
53530244185357725459535887783612:86:b0:4
- JIRA tasks:
- Notable versions:
- 8.5.0.11:
- Observed
12:86:e0:2
- Observed
- 8.7.1.3:
- TAC asserts fixed:
12:86:e0:2
- TAC asserts fixed:
- 8.7.1.4:
- Observed:
12:86:e0:2
- Observed:
- 8.7.1.5:
- TAC asserts fixed:
12:86:e0:212:86:e0:412:86:b0:4
- Observed:
12:86:b0:212:86:b0:412:86:e0:8
- TAC asserts fixed:
- 8.7.1.5_81619:
- Observed:
12:86:b0:4
- Observed:
- 8.7.1.6:
- TAC asserts fixed
12:86:b0:2
- TAC asserts fixed
- 8.5.0.11:
res-md-1 refuses clients
- Description: any client trying to use res-md-1 as a UAC cannot associate.
- Symptoms:
show lc-cluster load distribution clientshows 0 active and 0 standby clients for res-md-1.- started with res-md-1 crashing
- persisted across a reboot and code upgrade
- TAC cases
- Notable version:
- 8.7.1.4: crash that initiated the problem
- 8.7.1.5: observed
Holy amon logs, Batman!
- Description:
A debug trace on
amon_sender_procandamon_recvr_procis logged and cannot be disabled. Collectively, the controllers sent over 20,000 logs/s. The problem only showed up on some boots. - Bug IDs:
- AOS-210452
- TAC cases:
- Notable versions:
- 8.7.0.0: bug introduced
- 8.7.1.4: fixed
- JIRA task:
No state attribute in RADIUS request
- Description
- The RADIUS request packets do not contain the state attribute value and hence, clients face connectivity issue.
- Bug IDs
- AOS-207701
- AOS-218006
- Notable versions:
- 8.4.0.0: introduced
- 8.7.1.3: fixed
Too many pending changes
- Description
- If the expected output of
show configuration unsaved-nodeswas over 1024 characters, then it displayed nothing. - This also impacted API output.
- If the expected output of
- Bug IDs
- AOS-210404
- Notable versions:
- 8.5.0.10: observed broken
- 8.5.0.12: fixed
- 8.7.0.3: fixed
Prework
show global-user-table crashes auth module
- Description: Running said command on the MM often returns no results and
crashes the
authmodule 1-2 times. - Symptoms:
- Running
show global-user-table list mac <mac>hangs for about a minute, sometimes not returning anything. - When the command completely fails, it throws an error about the auth module being busy
show crashinfoshows that the auth module crashed 1 or 2 times- Happens via ssh and api.
- Running
- Workaround:
- Check each MD directly
- Try again later
- Notable versions:
- 8.7.1.4: observed
- 8.7.1.5: observed immediately after upgrade, but haven’t been able to recreate since
- 8.7.1.6: observed
APs crashing
- Description: A lot of APs crashing
- Symptoms:
- A few APs crash repeatedly (started keeping track in 8.7.1.5):
VAW-152TP01B(res)LIB-234BA1188L(col)
- A few APs crash repeatedly (started keeping track in 8.7.1.5):
Workaround
Delegated commands to v6 controllers fail
- Symptoms:
aaa user deletecommands from the MC do not ever get a response from the v6 controllers.- Running a second command requires waiting for the timeout (default 300 s)
- Recreate the problem:
- Have at least one MD connect to the MC over IPv6, and note which MD these
are.
To do this, configure them with the
masteripv6orconductoripv6command instead of themasteriporconductoripcommand.
This can be verified with the(isb-mm-1) [mynode] #cd vtc-md-1 (isb-mm-1) [00:1a:1e:04:b1:10] #show configuration committed | include conductor conductoripv6 2607:b400:2:2000:0:173:32:36 ipsec-factory-cert conductor-mac-1 20:4c:03:8f:53:1a conductor-mac-2 20:4c:03:0e:e0:44 interface-f vlan-f 100show switches debugcommand, noting which version is used in the “IP Address” column.(isb-mm-1) [mynode] #show switches debug All Switches ------------ IP Address MAC Name Nodepath Type Model Version Status Uptime CrashInfo Config Sync Time (sec) License Release Type ---------- --- ---- -------- ---- ----- ------- ------ ------ --------- ---------------------- ------- ------------ 128.173.32.34 20:4c:03:8f:53:1a isb-mm-1 /mm/mynode conductor ArubaMM-HW-10K 8.10.0.9_88493 up 51d 20h 50m no 0 N/A LSR 128.173.32.35 20:4c:03:0e:e0:44 isb-mm-2 /mm standby ArubaMM-HW-10K 8.10.0.9_88493 up 51d 20h 40m no 0 N/A LSR 172.16.1.11 00:1a:1e:02:d8:90 col-md-1 /md/vt/swva/col MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 13m no 0 N/A LSR 172.16.1.12 00:1a:1e:03:03:08 col-md-2 /md/vt/swva/col MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 13m yes 0 N/A LSR 172.16.1.13 00:1a:1e:02:d8:f0 col-md-3 /md/vt/swva/col MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 13m no 0 N/A LSR 172.16.1.14 00:1a:1e:03:02:78 col-md-4 /md/vt/swva/col MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 13m yes 0 N/A LSR 172.16.1.141 00:1a:1e:03:01:98 bur-md-1 /md/vt/swva/bur MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 19m no 0 N/A LSR 172.16.1.142 00:1a:1e:02:d8:b0 bur-md-2 /md/vt/swva/bur MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 19m yes 0 N/A LSR 172.16.1.143 00:1a:1e:02:d9:70 bur-md-3 /md/vt/swva/bur MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 18m no 0 N/A LSR 172.16.1.144 00:1a:1e:03:00:a8 bur-md-4 /md/vt/swva/bur MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 19m no 0 N/A LSR 172.17.1.11 00:1a:1e:03:00:d8 res-md-1 /md/vt/swva/res MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 9m yes 0 N/A LSR 172.17.1.12 00:1a:1e:03:01:90 res-md-2 /md/vt/swva/res MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 8m yes 0 N/A LSR 172.17.1.13 00:1a:1e:03:11:10 res-md-3 /md/vt/swva/res MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 9m yes 0 N/A LSR 172.17.1.14 00:1a:1e:03:0f:f8 res-md-4 /md/vt/swva/res MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 9m yes 0 N/A LSR 2607:b400:62:1400:0:16:247:11 00:1a:1e:04:b1:10 vtc-md-1 /md/vt/swva/vtc MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 3m no 0 N/A LSR 2607:b400:62:1400:0:16:247:12 00:1a:1e:04:b1:18 vtc-md-2 /md/vt/swva/vtc MD Aruba7240XM 8.10.0.9_88493 up 49d 7h 3m no 0 N/A LSR 172.16.236.151 00:1a:1e:00:14:30 nvc-md-1 /md/vt/nova/nvc MD Aruba7220 8.10.0.9_88493 up 49d 7h 5m no 0 N/A LSR 172.16.236.152 00:1a:1e:00:99:70 nvc-md-2 /md/vt/nova/nvc MD Aruba7220 8.10.0.9_88493 up 49d 7h 7m no 0 N/A LSR Total Switches:18 - From the MC, run a
aaa user delete ...command, then check the status:
Note that the two MDs with IP(isb-mm-1) [mynode] #aaa user delete mac 00:11:22:33:44:55 Users will be deleted at MDs. Please check show CLI for the status (isb-mm-1) [mynode] #aaa user delete mac 11:22:33:44:55:66 The previous CLI is still in progess, please try later! (isb-mm-1) [mynode] #show aaa user-delete-result Summary of user delete CLI requests ! Current user delete request timeout value: 300 seconds aaa user delete mac 00:11:22:33:44:55 , Overall Status- Response pending , Total users deleted- 0 MD IP : 172.16.1.11, Status- Complete , Count- 0 MD IP : 172.16.1.12, Status- Complete , Count- 0 MD IP : 172.16.1.13, Status- Complete , Count- 0 MD IP : 172.16.1.14, Status- Complete , Count- 0 MD IP : 172.16.1.141, Status- Complete , Count- 0 MD IP : 172.16.1.142, Status- Complete , Count- 0 MD IP : 172.16.1.143, Status- Complete , Count- 0 MD IP : 172.16.1.144, Status- Complete , Count- 0 MD IP : 172.17.1.11, Status- Complete , Count- 0 MD IP : 172.17.1.12, Status- Complete , Count- 0 MD IP : 172.17.1.13, Status- Complete , Count- 0 MD IP : 172.17.1.14, Status- Complete , Count- 0 MD IP : 0.0.0.0, Status- Response pending , Count- 0 MD IP : 0.0.0.0, Status- Response pending , Count- 0 MD IP : 172.16.236.151, Status- Complete , Count- 0 MD IP : 172.16.236.152, Status- Complete , Count- 00.0.0.0have a response pending. These are the two VTC MDs which are connecting the MC over IPv6. - After 300 seconds from when the delete command was run:
Note the command timed out.(isb-mm-1) [mynode] #show aaa user-delete-result Summary of user delete CLI requests ! Current user delete request timeout value: 300 seconds aaa user delete mac 00:11:22:33:44:55 , Overall Status- Complete , Total users deleted- 0 MD IP : 172.16.1.11, Status- Complete , Count- 0 MD IP : 172.16.1.12, Status- Complete , Count- 0 MD IP : 172.16.1.13, Status- Complete , Count- 0 MD IP : 172.16.1.14, Status- Complete , Count- 0 MD IP : 172.16.1.141, Status- Complete , Count- 0 MD IP : 172.16.1.142, Status- Complete , Count- 0 MD IP : 172.16.1.143, Status- Complete , Count- 0 MD IP : 172.16.1.144, Status- Complete , Count- 0 MD IP : 172.17.1.11, Status- Complete , Count- 0 MD IP : 172.17.1.12, Status- Complete , Count- 0 MD IP : 172.17.1.13, Status- Complete , Count- 0 MD IP : 172.17.1.14, Status- Complete , Count- 0 MD IP : 0.0.0.0, Status- Timed out , Count- 0 MD IP : 0.0.0.0, Status- Timed out , Count- 0 MD IP : 172.16.236.151, Status- Complete , Count- 0 MD IP : 172.16.236.152, Status- Complete , Count- 0
- Have at least one MD connect to the MC over IPv6, and note which MD these
are.
To do this, configure them with the
- Workaround:
- Run the command from the appropriate MD.
- TAC case:
API timeouts
- Description: API calls sometimes take a really long time.
- Symptoms:
- API calls time out.
- API login process can return a 401.
- TCP ACK to the API call is sent immediately, but the API response is still delayed.
- Root cause:
- The
arci-cli-helperprocess is single threaded. Yes, really. - This process appears to be the shim between the HTTP interface of the API and the system.
- This is less a “bug” and more of a “critical design failure”.
- The
- Recreate the problem:
- Make an API call for a command that takes a long time (e.g.,
show bss-table) - While that is still waiting on a response, make an API call for a command
that should be nearly instant (e.g.,
show version). - Note that the second call will not get a response until the first one finishes.
- Make an API call for a command that takes a long time (e.g.,
- TAC case:
aaa rfc-3576-server profiles are dumb
- Description: An rfc-3576 message’s sender is not recognized as a configured server.
-
Symptoms:
RADIUS RFC 3576 Statistics
--------------------------
Server Disconnect Req Disconnect Acc Disconnect Rej No Secret No Sess ID Bad Auth Invalid Req Pkts Dropped Unknown service CoA Req CoA Acc CoA Rej No perm
------ -------------- -------------- -------------- --------- ---------- -------- ----------- ------------ --------------- ------- ------- ------- -------
172.28.48.84 0 0 0 0 0 0 0 0 0 0 0 0 0
172.28.49.84 0 0 0 0 0 0 0 0 0 0 0 0 0
2607:b400:62:9200:0:8f:ee32:b3f3 0 0 0 0 0 0 0 0 0 0 0 0 0
2607:b400:62:9200:0:95:1b5d:6dfa 0 0 0 0 0 0 0 0 0 0 0 0 0
2607:b400:92:8400:0000:0044:7dcf:5796 0 0 0 0 0 0 0 0 0 0 0 0 0
2607:b400:92:8400:0000:0046:275b:4605 0 0 0 0 0 0 0 0 0 0 0 0 0
2607:b400:92:8500:0000:0041:89db:6313 0 0 0 0 0 0 0 0 0 0 0 0 0
2607:b400:92:8500:0000:004d:be0b:1156 0 0 0 0 0 0 0 0 0 0 0 0 0
Packets received from unknown clients : 1653
Packets received with unknown request : 0
Total RFC3576 packets Received : 1653
- Workaround:
- IPv6 addresses must be formatted omitting leading zeros, but also without
the use of a double colon (
::). - Different formats of the same address are recognized as different profiles.
- Incorrect:
2607:b400:0092:8400:0000:0044:7dcf:5796 - Incorrect:
2607:b400:92:8400::44:7dcf:5796 - Correct:
2607:b400:92:8400:0:44:7dcf:5796
- IPv6 addresses must be formatted omitting leading zeros, but also without
the use of a double colon (
ERR_IKESA_EXPIRED
- Description: Tunnel between MM and MD is broken.
- Symptoms:
- So far, this has only happened to col-md-r2:
- controller MAC:
00:0b:86:b4:d3:a7 - system serial:
CR0001355
- controller MAC:
- The problem has persisted after multiple factory resets.
- Cluster VRRP address is down for the impacted MD.
- So far, this has only happened to col-md-r2:
- Temporary workaround:
- To restore the tunnel, on the MM run:
process restart isakmpd
- To restore the tunnel, on the MM run:
- Long-term workaround:
- We moved the RAPs to lcc-col and decommissioned col-md-r2.
- Motivation was consolidation of controllers, not “fixing” this bug.
- TAC cases:
- JIRA tasks:
API issues
There are a lot of them.
Extra config
logging server
- API endpoint:
v1/configuration/object/log_lvl_syslog_ipv6_options - CLI config:
logging <ipv6 addr> [options]
Best way to explain this one is to show a series of POSTing to the endpoint, show the resulting config, GETting the endpoint, then POSTing the received json blob. Notably, these operations should be invertible. That is, POSTing what was received from the GET should do nothing.
POST:
[{ "ipv6addr": "2001:468:c80:210f:0:177:fd2a:cb4e" }]
Sets:
logging 2001:468:c80:210f:0:177:fd2a:cb4e
GET/POST:
[{
"ipv6addr": "2001:468:c80:210f:0:177:fd2a:cb4e",
"fac": "local1",
"lvl_severity": "warnings"
}]
Sets:
logging 2001:468:c80:210f:0:177:fd2a:cb4e facility local1 severity warnings
GET:
[{
"ipv6addr": "2001:468:c80:210f:0:177:fd2a:cb4e",
"facility": true,
"fac": "local1",
"severity": true,
"lvl_severity": "warnings"
}]
Missing config
- Description: Certain config items have an API object with no definition.
- Symptoms:
- These configuration items do not show up in the config JSON.
- The API endpoint can still be queried directly:
>>> # Configuration present >>> md.get(arubaos.api_object("telnet_cli")) {'_data': {'telnet_cli': {}}}>>> # Configuration not present >>> md.get(arubaos.api_object("telnet_cli")) {'_data': {'telnet_cli': None}} - Notably, all instances of this seem to have the API definition:
{ "type": "object" }
ipv6_enable
- API definition file:
Controller.josn - Full API endpoint path:
v1/configuration/object/ipv6_enable - CLI configuration:
ipv6 enable
telnet_cli
- API definition file:
Controller.json - Full API endpoint path:
v1/configuration/object/telnet_cli - CLI configuration:
telnet cli
telnet_soe
- API definition file:
Controller.json - Full API endpoint path:
v1/configuration/object/telnet_soe - CLI configuration:
telnet soe
ssh disable_dsa
- API definition file:
Authentication.json - Full API endpoint path:
v1/configuration/object/aaa_ssh_dsa - CLI configuration:
ssh disable_dsa
Note that when this command is present, DSA keys are disabled for ssh. Thus, when API returns:
{"_data": {"aaa_ssh_dsa": {}}}
DSA keys are disabled, counter to the natural reading of the output.
Can’t upgrade via API
- Description: Trying to execute commands used in an upgrade process via API throws permission errors.
- Symptoms:
- Sample interactive python session:
>>> import arubaos.arubaos as aos >>> import passpy >>> domain = "mobility.nis.vt.edu" >>> creds = {"username": waldrep, "pwpath": "waldrep@vt.edu/netadmin"} >>> vtc1 = aos.Controller(f"vtc-md-1."{domain}, creds} >>> endpoint = aos.api_object("copy_scp_system") >>> body = { ... "scphost": "2001:468:c80:210f:0:165:9b7d:7dcb", ... "username": "waldrep", ... "passwd": passpy.store.Store() \ ... .get_key("waldrep@vt.edu/conehead") \ ... .split('\n', maxsplit=1)[0], ... "filename": "C_ArubaOS_72xx_8.7.1.5_81619", ... "partition_num": "partition1" ... } >>> vtc1.post(endpoint, body) {'_global_result': {'status': 1, 'status_str': 'You do not have permissions to execute the commands'}}- Including or excluding the optional
partition_nummakes no difference. - Using a v4 or v6 scphost makes no difference.
- Same error when trying to preload APs:
>>> endpoint = aos.api_object("ap_image_preload") >>> body = {'ap_info': 'all-aps' }
- Workaround:
- Upload via webui or cli
Inconsistent errors for not being authenticated/authorized
- Trying to do something without being logged in returns the HTML for the login
page and a
401code. - Trying to do something that the user’s role is not allowed to do returns:
- code
200 - The following XML:
<aruba> <status>Error</status> <reason>no permission to execute opcode/program.</reason> </aruba>
- code
- Trying to do something that should be allowed but is broken (like upgrading
the OS image):
- code
200 - The following JSON:
{ '_global_result': { 'status': 1, 'status_str': 'You do not have permissions to execute the commands' } }
- code
- Using an invalid
showcommand (e.g.,show ap database long}):- code
200 - empty HTTP payload
- code
Leaking secrets
Using a read-only account to get certain items reveals secrets, such as snmp community secrets, radius keys, etc.
At least for a cluster’s vrrp secret, it seems to become obfuscated on reboot.
Ordering of unordered things
Things that have no inherent ordering (such as a virtual_ap definition) is
returned in a list, which is ordered.
Nor is there any metadata which indicates which things are order sensitive and
which are not.
Actual:
{
"virtual_ap": [
{
"aaa_prof": {
"profile-name": "aaa-eduroam"
},
"drop_mcast": {},
"profile-name": "vap-eduroam",
"ssid_prof": {
"profile-name": "ssid-eduroam"
},
"vlan": {
"vlan": "vlan-user"
}
},
{
"aaa_prof": {
"profile-name": "aaa-vtopenwifi"
},
"drop_mcast": {},
"profile-name": "vap-vtopenwifi",
"ssid_prof": {
"profile-name": "ssid-vtopenwifi"
},
"vlan": {
"vlan": "vlan-user"
}
}
],
"ap_group": [
{
"dot11a_prof": {
"profile-name": "rpa-default"
},
"profile-name": "agp-ageng",
"reg_domain_prof": {
"profile-name": "rdp-blacksburg"
},
"virtual_ap": [
{
"profile-name": "vap-eduroam"
},
{
"profile-name": "vap-vtopenwifi"
}
]
}
]
}
Better:
{
"virtual_ap": {
"_data": [
{
"aaa_prof": {
"profile-name": "aaa-eduroam"
},
"drop_mcast": {},
"profile-name": "vap-eduroam",
"ssid_prof": {
"profile-name": "ssid-eduroam"
},
"vlan": {
"vlan": "vlan-user"
}
},
{
"aaa_prof": {
"profile-name": "aaa-vtopenwifi"
},
"drop_mcast": {},
"profile-name": "vap-vtopenwifi",
"ssid_prof": {
"profile-name": "ssid-vtopenwifi"
},
"vlan": {
"vlan": "vlan-user"
}
}
],
"_flags": {
"ordered": false
}
},
"ap_group": {
"_data": [
{
"dot11a_prof": {
"profile-name": "rpa-default"
},
"profile-name": "agp-ageng",
"reg_domain_prof": {
"profile-name": "rdp-blacksburg"
},
"virtual_ap": {
"_data": [
{
"profile-name": "vap-eduroam"
},
{
"profile-name": "vap-vtopenwifi"
}
],
"_flags": {
"ordered": false
}
}
}
],
"_flags": {
"ordered": false
}
}
}
Best:
{
"virtual_ap": {
"vap-eduroam": {
"aaa_prof": "aaa-eduroam",
"drop_mcast": {},
"ssid_prof": "ssid-eduroam",
"vlan": "vlan-user"
},
"vap-vtopenwifi": {
"aaa_prof": "aaa-vtopenwifi",
"drop_mcast": {},
"ssid_prof": "ssid-vtopenwifi",
"vlan": "vlan-user"
}
},
"ap_group": {
"apg-ageng": {
"dot11a_prof": "rpa-default",
"profile-name": "agp-ageng",
"reg_domain_prof": "rdp-blacksburg",
"virtual_ap": {
"vap-eduroam": {},
"vap-vtopenwifi": {}
}
}
}
}
Unpredictable ordering
Making the above problem worse, such ordering is somewhat static. It seems to be the order is altered when the device reboots.
Initial setup
- DNS checks fail if you do a permanent network setup without doing a temporary config first.
- GUI password as set in the setup doesn’t work. Resetting the password through the cli to the same things as setup initially makes it work.
First run
- Initial log in goes to a “not authorized” page, which then redirects to a log out page… which does nothing. Manually going to the cluster domain again redirects to the main COP page… logged in.
Uploading a certificate
- I have yet to be successful in uploading a PEM.
Things attempted:
- Uploading a fully cat-ed chain (i.e., leaf, key, and intermediate)
- Uploading the root and intermediate certs explicitly as a CA, then uploading the leaf/key PEM.
- When uploading a PEM fails, the entire HTTP process dies, and the only way to recover is to rebuild COP (or probably TAC intervention).
- SANs are not checked when uploading a certificate. A typo here can take the whole server down.
- Uploading a second CA cert seems to override the first.
- What does work is uploading a PKCS12, which contains the server cert, key,
and intermediate cert(s).
Although, this still throws an error message.

Missing features
- There is no way to upload the certificate from the cli.
- There is no way to upload a server certificate without applying it. This makes it impossible to stage a change.